Chapter 2 Linear regression
2.1 Motivation
The questions we wish to answer with linear regression are of the kind depicted in Figure 2.1: What drives spatial variation in annual average precipitation and annual average temperature? In the case of precipitation, the main drivers seem to be continentality and elevation, plus a few minor drivers. Temperature appears to be dominantly controlled by elevation only. Linear regression examines this question by modelling a response variable against one or more predictor variables, while the relationship between the two is linear in its parameters.
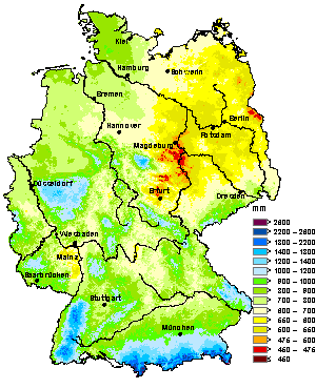
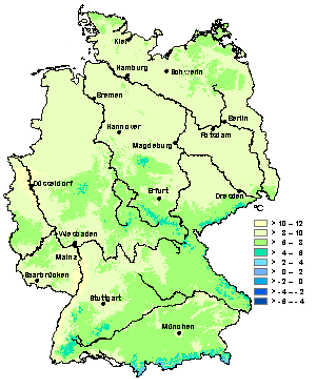
Figure 2.1: Maps of annual average precipitation (left) and annual average air temperature (right) over Germany from 1961 to 1990. Source: https://www.dwd.de/EN/climate_environment/climateatlas/climateatlas_node.html.
2.2 The linear model
The most general form of a linear model is:
\[\begin{equation} y = \beta_0 + \sum_{j=1}^{p}\beta_j \cdot x_j + \epsilon \tag{2.1} \end{equation}\] In this equation, \(y\) is the response variable (also called dependent or output variable), \(x_j\) are the predictor variables (also called independent, explanatory, input variables or covariates), \(\beta_0, \beta_1, \ldots, \beta_p\) are the parameters and \(\epsilon\) is the residual, i.e. that part of the response which remains unexplained by the predictors.
In the case of one predictor, which has come to be known as linear regression, the linear model is:
\[\begin{equation} y = \beta_0 + \beta_1 \cdot x + \epsilon \tag{2.2} \end{equation}\] It can be visualised as a line, with \(\beta_0\) being the intercept, where the line intersects the vertical axis \((x=0)\), and \(\beta_1\) being the slope of the line (Figure 2.2). Note, the point \(\left(\bar{x},\bar{y}\right)\), the centroid of the data, always lies on the line.
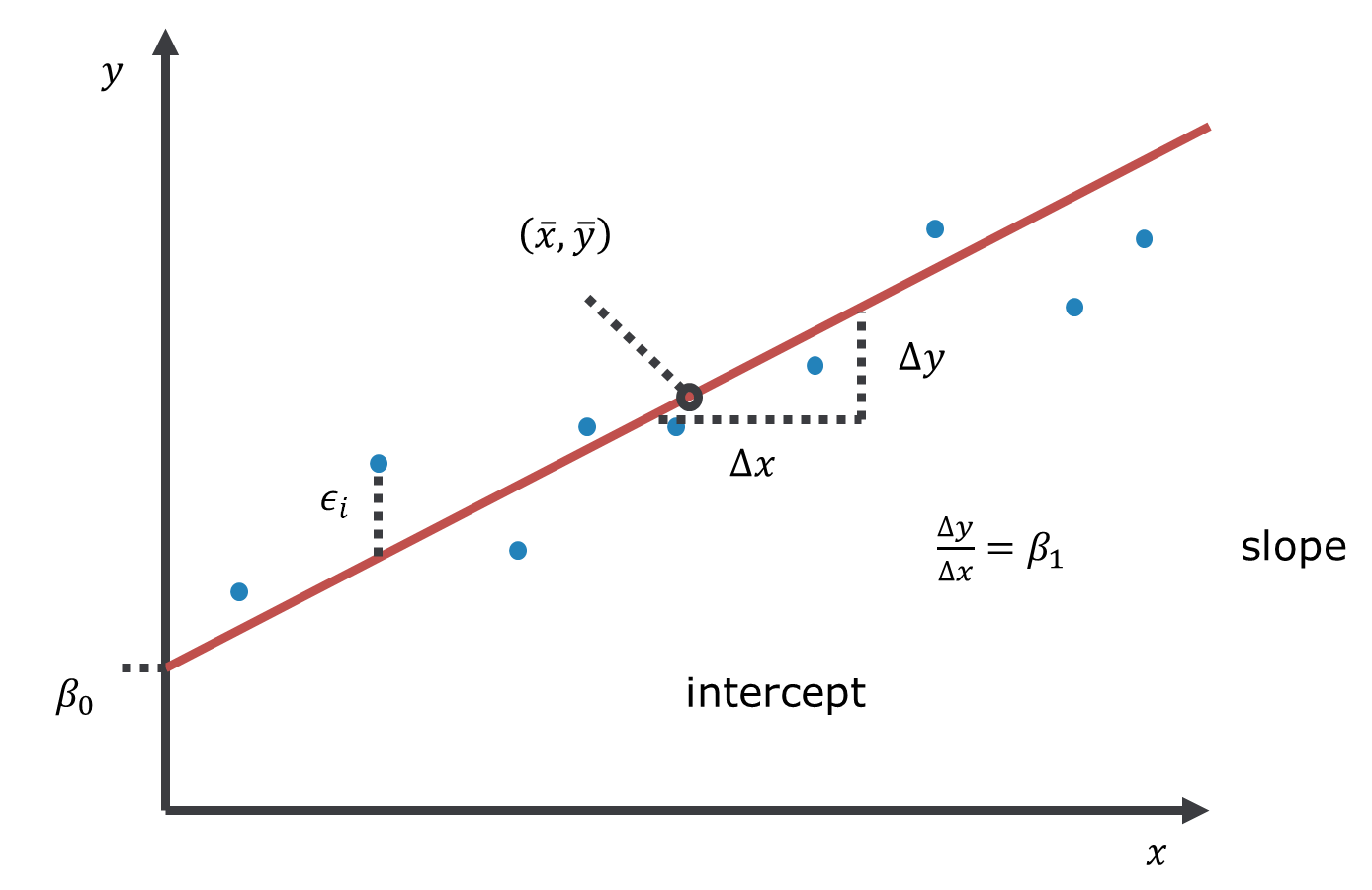
Figure 2.2: Linear model with one predictor variable (linear regression).
Linear means linear in terms of the model parameters, not (necessarily) in terms of the predictor variables. With this in mind, consider the following five models. Which are linear models, which are non-linear models? (Q1)1
\[\begin{equation} y = \beta_0 + \beta_1 \cdot x_1 + \beta_2 \cdot x_2 + \epsilon \tag{2.3} \end{equation}\] \[\begin{equation} y = \beta_0 + \beta_1 \cdot x_1^{\beta_2} + \epsilon \tag{2.4} \end{equation}\] \[\begin{equation} y = \beta_0 + \beta_1 \cdot x_1^3 + \beta_2 \cdot x_1 \cdot x_2 + \epsilon \tag{2.5} \end{equation}\] \[\begin{equation} y = \beta_0 + \exp(\beta_1 \cdot x_1) + \beta_2 \cdot x_2 + \epsilon \tag{2.6} \end{equation}\] \[\begin{equation} y = \beta_0 + \beta_1 \cdot \log x_1 + \beta_2 \cdot x_2 + \epsilon \tag{2.7} \end{equation}\]
We can also write the linear model equation with the data points explicitly indexed by \(i\) for \(i=1, 2, \ldots, n\). We have omitted the index previously for ease of reading:
\[\begin{equation} y_i = \beta_0 + \sum_{j=1}^{p}\beta_j \cdot x_{ij} + \epsilon_i \tag{2.8} \end{equation}\] The data points could be repeat measurements in time or in space.
We can also write the model more compactly in matrix form:
\[\begin{equation} y = \mathbf{X} \cdot \beta + \epsilon \tag{2.9} \end{equation}\]
With \(y = \begin{pmatrix} y_1\\ y_2\\ y_3 \end{pmatrix}\), \(\beta = \begin{pmatrix} \beta_0\\ \beta_1\\ \beta_2\\ \beta_3 \end{pmatrix}\), \(\epsilon = \begin{pmatrix} \epsilon_1\\ \epsilon_2\\ \epsilon_3 \end{pmatrix}\) and \(\mathbf{X} = \begin{pmatrix} 1 & x_{11} & x_{12} & x_{13}\\ 1 & x_{21} & x_{22} & x_{23}\\ 1 & x_{31} & x_{32} & x_{33} \end{pmatrix}\), the latter being the design matrix which summarises the predictor data.
When we talk about the linear model, the response variable is always continuous, while the predictor variables can be continuous, categorical or mixed. In principle, each of these variants can be treated mathematically in the same way, e.g. all can be analysed using the lm() function in R. However, historically different names have been established for these variants, which are worth mentioning here to avoid confusion (Tables 2.1 and 2.2).
| Continuous predictors |
Categorical predictors |
Mixed predictors |
|---|---|---|
| Regression | Analysis of variance (ANOVA) |
Analysis of covariance (ANCOVA) |
| 1 predictor variable | >1 predictor variables | |
|---|---|---|
| 1 response variable | Regression | Multiple regression |
| >1 response variables | Multivariate regression | Multivariate multiple regression |
2.3 Description versus prediction
The primary purpose of regression analysis is the description (or explanation) of the data in terms of a general relationship pertaining to the population that these data are sampled from. Being a property of the population, this relationship should then also allow us to make predictions, but we need to be careful. Consider the relationship between year and world record time for the men’s mile depicted in Figure 2.3. When the predictor is time, as shown here, regression becomes a form of trend analysis, in this case of how the record time in the male competition decreased over the years. We will talk about the R code and output further below, here we are just interested in the linear predictions.
# load mile data from remote repository
mile <- read.csv("https://raw.githubusercontent.com/avehtari/ROS-Examples/master/Mile/data/mile.csv", header=TRUE)
# fit linear model to data from 1st half of 20th century
fit1 <- lm(seconds ~ year, data = mile[mile$year<1950,])
# extract information about parameter estimates
coef(summary(fit1))## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 912.2340 67.90140 13.435 3.615e-08
## year -0.3439 0.03509 -9.798 9.059e-07## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1006.876 21.532 46.76 1.361e-29
## year -0.393 0.011 -35.73 3.780e-26# plot fit for 1st half of 20th century
plot(mile$year[mile$year<1950], mile$seconds[mile$year<1950],
xlim = c(1900, 2000), ylim = c(200, 260),
pch = 19, type = 'p',
xlab = "Year", ylab = "World record, men's mile (seconds)")
abline(coef(fit1), lwd = 3, col = "red")
# plot extrapolation to 2nd half of 20th century
plot(mile$year, mile$seconds,
xlim = c(1900, 2000), ylim = c(200, 260),
pch = 19, type = 'p',
xlab = "Year", ylab = "World record, men's mile (seconds)")
abline(coef(fit1), lwd = 3, col = "red")
# plot all-data fit until 2050
plot(mile$year, mile$seconds,
xlim = c(1900, 2050), ylim = c(200, 260),
pch = 19, type = 'p',
xlab = "Year", ylab = "World record, men's mile (seconds)")
abline(coef(fit2), lwd = 3, col = "red")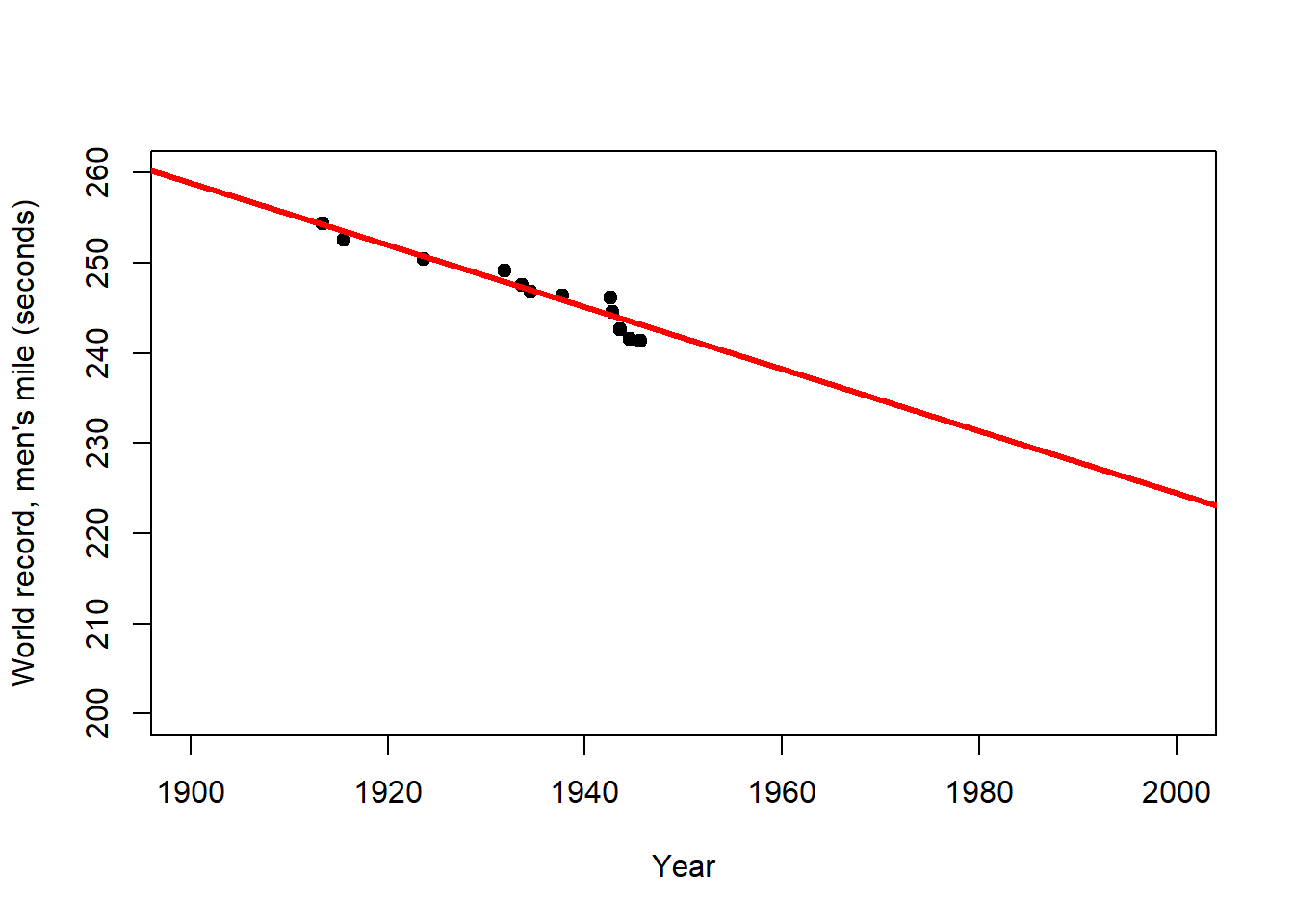
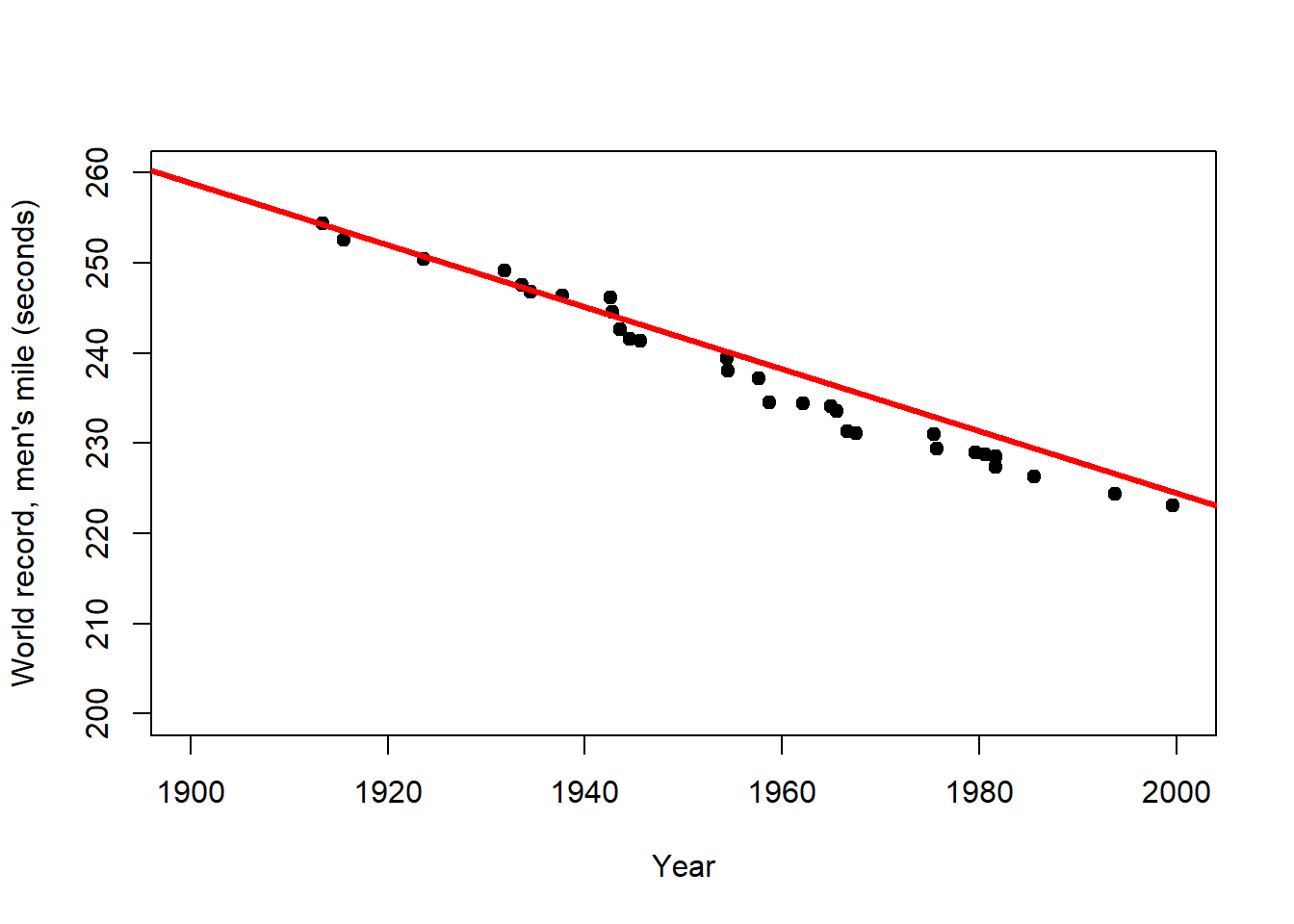
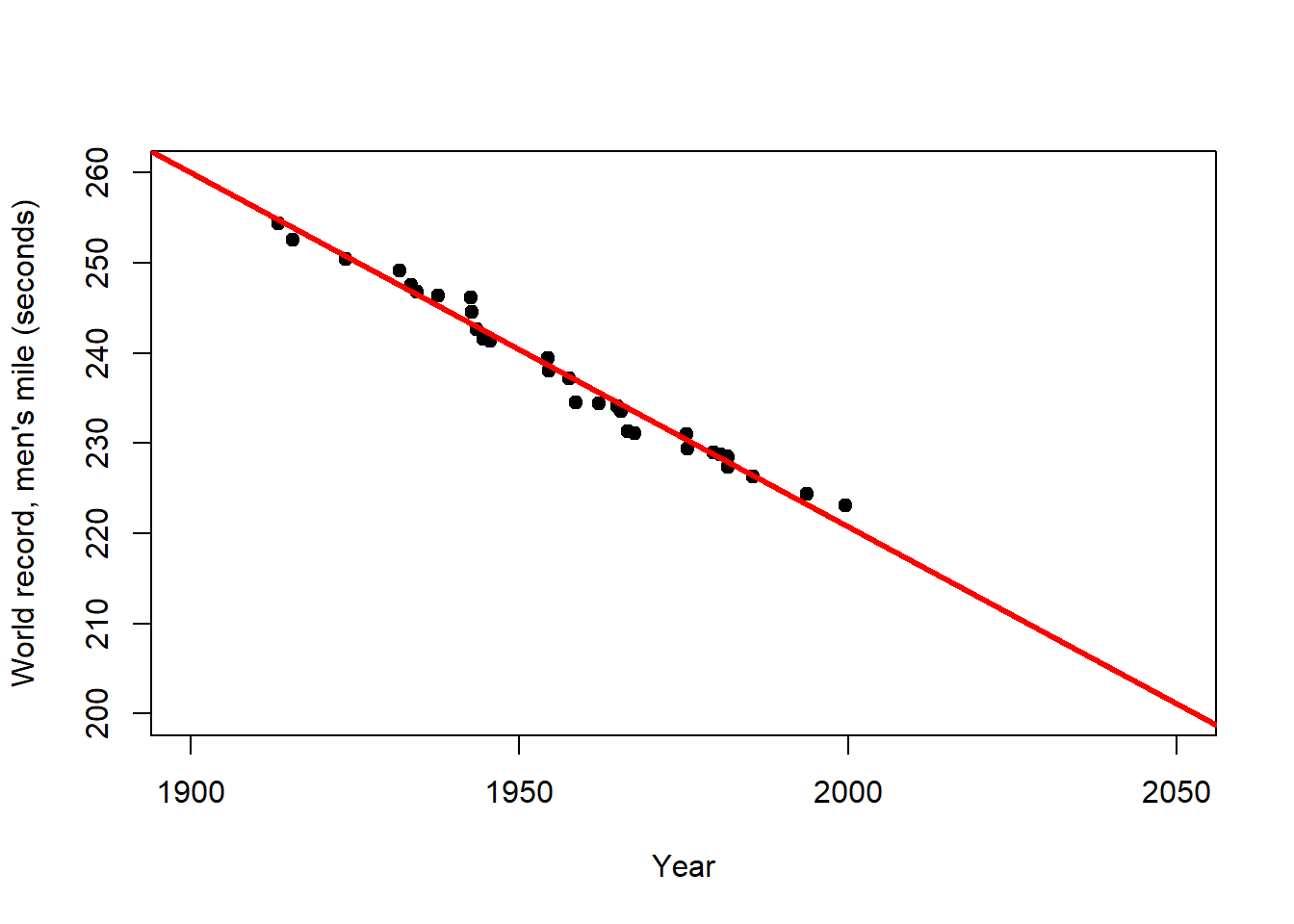
Figure 2.3: Left: Trend of the world record for the men`s mile over the first half of the 20th century (description). Centre: Extrapolation of this trend over the 2nd half of the 20th century (prediction). Right: Extrapolation of the overall trend until the year 2050 (longer prediction). After: Wainer (2009)
The world record for the men`s mile improved linearly over the first half of the 20th century (Figure 2.3, left). This trend provides a remarkably accurate fit for the second half of the century as well (Figure 2.3, centre). However, for how long can the world record continue to improve at the same rate (Figure 2.3, right)? This example clearly shows that the scope for prediction by regression lies within certain bounds, and highlights the limits of these simple models for making distant predictions (e.g. in time and space). In the case of the world record we would expect the rate of improvement to decline with time, i.e. the world record to level off, which calls for a non-linear model.
2.4 Linear Regression
Typically, regression problems are solved, i.e. the lines in Figures 2.2 and 2.3 are fitted to the data, by minimising the Sum of Squared Errors (SSE) between the regression line and the data points. This method has become known as Least Squares. Graphically, it means that in Figure 2.2 we try different lines with different intercepts \(\left(\beta_0\right)\) and slopes \(\left(\beta_1\right)\) and ultimately choose the one where the sum over all vertical distances \(\epsilon_i\) squared is smallest. Mathematically, SSE is defined as:
\[\begin{equation} SSE=\sum_{i=1}^{n}\left(\epsilon_i\right)^2=\sum_{i=1}^{n}\left(y_i-\left(\beta_0+\beta_1 \cdot x_i\right)\right)^2 \tag{2.10} \end{equation}\] The terms \(\epsilon_i=y_i-\left(\beta_0+\beta_1 \cdot x_i\right)\) are called the residuals, i.e. that part of the variation in the data which the linear model cannot explain.
In the case of linear regression, SSE can be minimised analytically, which is not the case for non-linear models, for example. Analytically, we find the minimum of SSE where its partial derivatives with respect to the two model parameters are both zero (compare Chapter 1): \(\frac{\partial SSE}{\partial \beta_0}=0\) and \(\frac{\partial SSE}{\partial \beta_1}=0\). Using the definition of SEE of Equation (2.10) we thus begin with a system of two differential equations:
\[\begin{equation} \frac{\partial SSE}{\partial \beta_0}=-2 \cdot \sum_{i=1}^{n}\left(y_i-\beta_0-\beta_1 \cdot x_i\right)=0 \tag{2.11} \end{equation}\] \[\begin{equation} \frac{\partial SSE}{\partial \beta_1}=-2 \cdot \sum_{i=1}^{n}x_i \cdot \left(y_i-\beta_0-\beta_1 \cdot x_i\right)=0 \tag{2.12} \end{equation}\] We have already calculated these derivatives in an exercise in Chapter 1 using the sum rule and the chain rule in particular. Since Equations (2.11) and (2.12) form a system of two differential equations with two unknowns (\(\beta_0\) and \(\beta_1\); the data points \(x_i\) and \(y_i\) are known) we can solve it exactly.
First, we solve Equation (2.11) for \(\beta_0\) (after dividing by -2):
\[\begin{equation} \sum_{i=1}^{n}y_i-n \cdot \beta_0-\beta_1 \cdot \sum_{i=1}^{n}x_i=0 \tag{2.13} \end{equation}\] \[\begin{equation} n \cdot \hat\beta_0=\sum_{i=1}^{n}y_i-\hat\beta_1 \cdot \sum_{i=1}^{n}x_i \tag{2.14} \end{equation}\] \[\begin{equation} \hat\beta_0=\bar{y}-\hat\beta_1 \cdot \bar{x} \tag{2.15} \end{equation}\] Note, at some point we have renamed \(\beta_0\) to \(\hat\beta_0\) and \(\beta_1\) to \(\hat\beta_1\) to denote these as estimates. The parameter notation up to now has been general but as we approach actual numerical values for the data at hand we are using the “hat” symbol to signify that we are now calculating estimates of those general parameters for a given dataset.
Second, we insert Equation (2.15) into Equation (2.12) (again after dividing by -2 and rearranging):
\[\begin{equation} \sum_{i=1}^{n}\left(x_i \cdot y_i-\beta_0 \cdot x_i-\beta_1 \cdot x_i^2\right)=0 \tag{2.16} \end{equation}\] \[\begin{equation} \sum_{i=1}^{n}\left(x_i \cdot y_i-\bar{y} \cdot x_i+\hat\beta_1 \cdot \bar{x} \cdot x_i-\hat\beta_1 \cdot x_i^2\right)=0 \tag{2.17} \end{equation}\]
Third, we solve Equation (2.17) for \(\hat\beta_1\):
\[\begin{equation} \sum_{i=1}^{n}\left(x_i \cdot y_i-\bar{y} \cdot x_i\right)-\hat\beta_1 \cdot \sum_{i=1}^{n}\left(x_i^2-\bar{x} \cdot x_i\right)=0 \tag{2.18} \end{equation}\] \[\begin{equation} \hat\beta_1=\frac{\sum_{i=1}^{n}\left(x_i \cdot y_i-\bar{y} \cdot x_i\right)}{\sum_{i=1}^{n}\left(x_i^2-\bar{x} \cdot x_i\right)} \tag{2.19} \end{equation}\]
Via a series of steps that I skip here, we arrive at:
\[\begin{equation} \hat\beta_1=\frac{SSXY}{SSX} \tag{2.20} \end{equation}\] Where \(SSX=\sum_{i=1}^{n}\left(x_i-\bar{x}\right)^2\) and \(SSXY=\sum_{i=1}^{n}\left(x_i-\bar{x}\right) \cdot \left(y_i-\bar{y}\right)\). Note, analogously \(SSY=\sum_{i=1}^{n}\left(y_i-\bar{y}\right)^2\). Equation (2.20) is an exact solution for \(\hat\beta_1\).
We then insert Equation (2.20) back into Equation (2.10) and have an exact solution for \(\hat\beta_0\).
2.5 Significance of regression
Having estimates for the regression parameters, classical statistics then asks whether these estimates are “statistically significant” or could have arisen by chance from the (assumed) random process of sampling the data.2 We do this via Analysis of Variance (ANOVA), which begins by constructing the ANOVA table (Table 2.3). This is often done in the background in software like R and not actually looked at that much.
| Source | Sum of squares |
Degrees of freedom \((df)\) | Mean squares | F statistic \(\left(F_s\right)\) | \(\Pr\left(Z\geq F_s\right)\) |
|---|---|---|---|---|---|
| Regression | \(SSR=\\SSY-SSE\) | \(1\) | \(\frac{SSR}{df_{SSR}}\) | \(\frac{\frac{SSR}{df_{SSR}}}{s^2}\) | \(1-F\left(F_s,1,n-2\right)\) |
| Error | \(SSE\) | \(n-2\) | \(\frac{SSE}{df_{SSE}}=s^2\) | ||
| Total | \(SSY\) | \(n-1\) |
In the second column of Table 2.3, \(SSY=\sum_{i=1}^{n}\left(y_i-\bar{y}\right)^2\) is a measure of the total variance of the data, i.e. how much the data points are varying around the overall mean (Figure 2.4, left).
\(SSE=\sum_{i=1}^{n}\left(\epsilon_i\right)^2=\sum_{i=1}^{n}\left(y_i-\left(\beta_0+\beta_1 \cdot x_i\right)\right)^2\) is a measure of the error variance, i.e. how much the data points are varying around the regression line (Figure 2.4, right). This is the variance not explained by the model.
\(SSR=SSY-SSE\) then is a measure of the variance explained by the model.
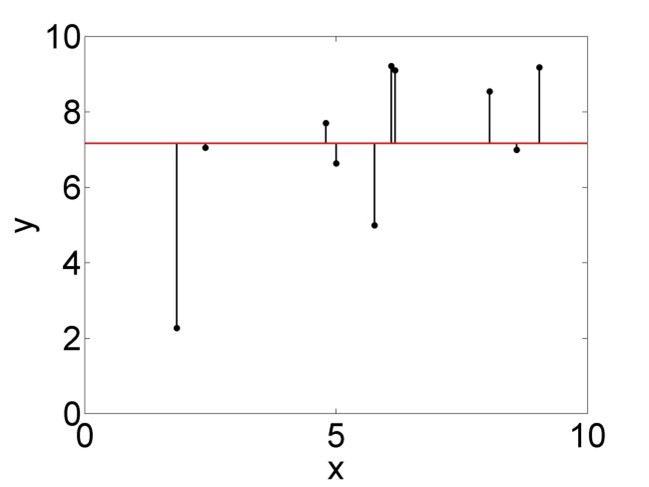
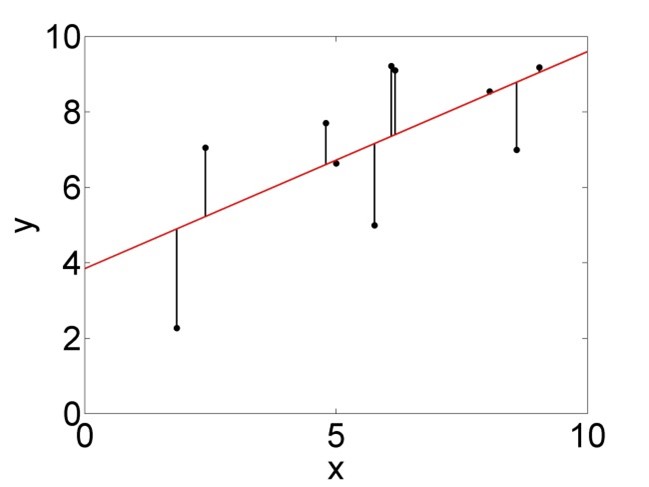
Figure 2.4: Variation of the data points around the mean, summarised by \(SSY\) (left), and around the regression line, summarised by \(SSE\) (right).
The third column of Table 2.3 lists the so called degrees of freedom of the three variance terms, which can be understood as the number of free parameters for the respective term that is controlled by the (assumed) random process of sampling the data. It is the number of possibilities for the chance process to unfold. \(SSY\) requires one parameter \(\left(\bar{y}\right)\) to be calculated from the data (see above). Hence the degrees of freedom are \(n-1\); if I know \(\bar{y}\) then there are \(n-1\) data points left that can be generated by chance, the \(n\)th one I can calculate from all the others and \(\bar{y}\). \(SSE\), in turn, requires two parameters (\(\beta_0\) and \(\beta_1\)) to be calculated from the data (Equations (2.15) and (2.20)). Hence the degrees of freedom are \(n-2\). The degrees of freedom of \(SSR\) then are just the difference between the former two; \(df_{SSR}=df_{SSY}-df_{SSE}=1\). The degrees of freedom are used to normalise the variance terms in the fourth column of Table 2.3, where \(s^2\) is called the error variance.
In the fifth column of Table 2.3 we find the ratio of two variances; regression variance over error variance. A “significant” regression is conceptualised as having a regression variance (explained by the model) that is much larger than the error variance (unexplained by the model). This is an F-Test problem, testing whether the variance explained by the model is significantly different from the variance unexplained by the model. The ratio of the two variances serves as the F statistic \(\left(F_s\right)\).
The sixth column of Table 2.3 then shows the p-value of the F-Test, i.e. the probability of getting \(F_s\) or a larger value (i.e. an even better model) by chance if the Null hypothesis \(\left(H_0\right)\) is true. \(H_0\) here is that the two variances are equal. It can be shown mathematically that \(F_s\) follows an F-distribution with parameters \(1\) and \(n-2\) under the Null hypothesis (Figure 2.5). The red line in Figure 2.5 marks a particular value of \(F_s\) (here between 10 and 11) and the corresponding value of the cumulative distribution function of the F-distribution \(\left(F\left(F_s,1,n-2\right)\right)\). The p-value is \(\Pr\left(Z\geq F_s\right)=1-F\left(F_s,1,n-2\right)\), i.e. the probability of getting this variance ratio or a greater one by chance (due to the random sampling process) even if the two variances are actually equal. Here, the p-value is very small and hence we conclude that the regression is “significant”.
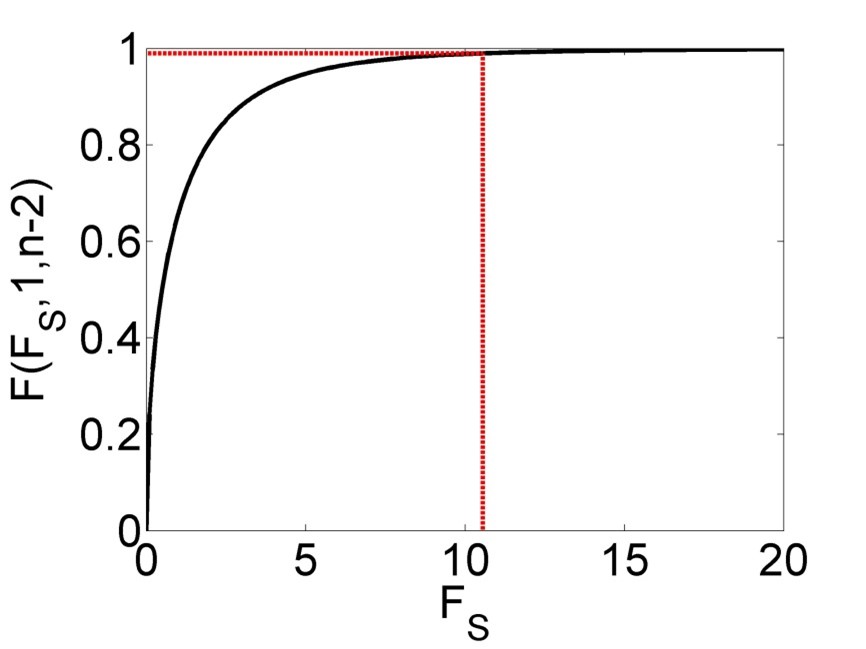
Figure 2.5: Cumulative distribution function (CDF) of the F-distribution of the F statistic \(\left(F_s\right)\), with a particular value and corresponding value of the CDF marked in red.
The correct interpretation of the p-value is a bit tricky. In the words of philosopher of science Ian Hacking (2001), if we have a p-value of say 0.01 this means “either the Null hypothesis is true, in which case something unusual happened by chance (probability 1%), or the Null hypothesis is false.” This means, the p-value is not the probability of the Null hypothesis being true; it is the probability of the data to come about if the Null hypothesis were true. If this is a very low probability then we think this tells us something about the Null hypothesis (that perhaps we should reject it), but in a roundabout way. Note, in the case of linear regression, the Null model is \(\beta_1=0\), i.e. \(y=\beta_0\) with \(\hat\beta_0=\bar{y}\), which means the overall mean is the best model summarising the data (Figure 2.4, left).
2.6 Confidence in parameter estimates
Having established the statistical significance of the regression, we typically look at the uncertainty around the parameter estimates. In classic linear regression this uncertainty is conceptualised as arising purely from the random sampling process; the data at hand are just one possibility of many, and in each alternative case the parameter estimates would have turned out slightly different. The linear model itself is assumed to be correct.
The first step in establishing how confident we should be that the parameter estimates are correct is the calculation of standard errors. For \(\hat\beta_0\) this is (derivation not shown here):
\[\begin{equation} s_{\hat\beta_0}=\sqrt{\frac{\sum_{i=1}^{n}x_i^2}{n} \cdot \frac{s^2}{SSX}} \tag{2.21} \end{equation}\]
Breaking down this formula into its individual parts, we can see that the more data points \(n\) we have, the smaller the standard error gets, i.e. the more confidence we should have in the estimate. Also, the larger the variation in \(x\) \((SSX)\) the smaller the standard error. Both effects make intuitive sense: the more data points we have and the more possibilities for \(x\) we have covered in our data, the more we can be confident that we have not missed much in our random sample. Conversely, the larger the error variance \(s^2\), i.e. the smaller the explanatory power of our model, the larger the standard error. And, the more \(x\) data points we have away from zero, i.e. the greater \(\sum_{i=1}^{n}x_i^2\), the smaller our confidence in the intercept (where \(x=0\)) and hence the standard error increases.
The standard error for \(\hat\beta_1\) is:
\[\begin{equation} s_{\hat\beta_1}=\sqrt{\frac{s^2}{SSX}} \tag{2.22} \end{equation}\]
The same interpretation applies, except there is no influence of the magnitude of the \(x\) data points.
We can also establish a standard error for new predictions \(\hat y\) for given new predictor values \(\hat x\):
\[\begin{equation} s_{\hat y}=\sqrt{s^2 \cdot \left(\frac{1}{n}+\frac{\left(\hat x-\bar x\right)^2}{SSX}\right)} \tag{2.23} \end{equation}\]
The same interpretation applies again, except there now is an added term \(\left(\hat x-\bar x\right)^2\) which means the further the new \(x\) value is away from the centre of the original data (the training or calibration data) the greater the standard error of the new prediction, i.e. the lower the confidence in it being correct. Note, the formulas for the standard errors arise from the fundamental assumptions of linear regression, which will be covered below. This can be shown mathematically but is omitted here.
From the standard errors we can calculate confidence intervals for the parameter estimates as follows:
\[\begin{equation} \Pr\left(\hat\beta_0-t_{n-2;0.975} \cdot s_{\hat\beta_0}\leq \beta_0\leq \hat\beta_0+t_{n-2;0.975} \cdot s_{\hat\beta_0}\right)=0.95 \tag{2.24} \end{equation}\]
The symbol \(\Pr(\cdot)\) means probability. The symbol \(t_{n-2;0.975}\) stands for the 0.975-percentile of the t-distribution with \(n-2\) degrees of freedom. Equation (2.24) is the central 95% confidence interval, which is defined as the bounds in which the “true” parameter, here \(\beta_0\), lies with a probability of 0.95. We can write the interval like this:
\[\begin{equation} CI=\left[\hat\beta_0-t_{n-2;0.975} \cdot s_{\hat\beta_0};\hat\beta_0+t_{n-2;0.975} \cdot s_{\hat\beta_0}\right] \tag{2.25} \end{equation}\]
As can be seen, the confidence interval \(CI\) is symmetric around the parameter estimate \(\hat\beta_0\) and arises from a t-distribution with parameter \(n-2\) whose width is modulated by the standard error \(s_{\hat\beta_0}\). Note, the width of the t-distribution is also controlled by sample size; it becomes narrower with increasing \(n\).
The same formulas apply for \(\beta_1\) and \(y\):
\[\begin{equation} \Pr\left(\hat\beta_1-t_{n-2;0.975} \cdot s_{\hat\beta_1}\leq \beta_1\leq \hat\beta_1+t_{n-2;0.975} \cdot s_{\hat\beta_1}\right)=0.95 \tag{2.26} \end{equation}\] \[\begin{equation} \Pr\left(\hat y-t_{n-2;0.975} \cdot s_{\hat y}\leq y\leq \hat y+t_{n-2;0.975} \cdot s_{\hat y}\right)=0.95 \tag{2.27} \end{equation}\]
As with the p-value, we need to be clear about the meaning of probability here, which in classic statistics is predicated on the repeated sampling principle. The meaning of the 95% confidence interval then is that in an assumed infinite number of regression experiments the 95% confidence interval captures the true parameter value in 95% of the cases. Again, this is not a probability of the true parameter value lying within the confidence interval for any one experiment!
The formulas for the confidence intervals (Equations (2.24), (2.26) and (2.27)) arise from the fundamental assumptions of linear regression; the residuals are independent identically distributed (iid) according to a normal distribution and the linear model is correct. Then it can be shown mathematically that \(\frac{\hat\beta_0-\beta_0}{s_{\hat\beta_0}}\), \(\frac{\hat\beta_1-\beta_1}{s_{\hat\beta_1}}\) and \(\frac{\hat y-y}{s_{\hat y}}\) are \(t_{n-2}\)-distributed (t-distribution with \(n-2\) degrees of freedom). Since the central 95% confidence interval of an arbitrary \(t_{n-2}\)-distributed random variable \(Z\) is \(\Pr\left(-t_{n-2;0.975}\leq Z\leq t_{n-2;0.975}\right)=0.95\) (Figure 2.6), we can substitute any of the aforementioned three terms for \(Z\) and rearrange to arrive at Equations (2.24), (2.26) and (2.27).
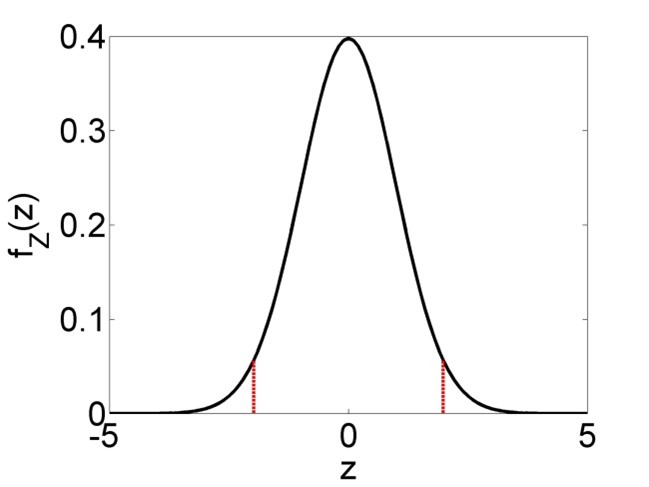
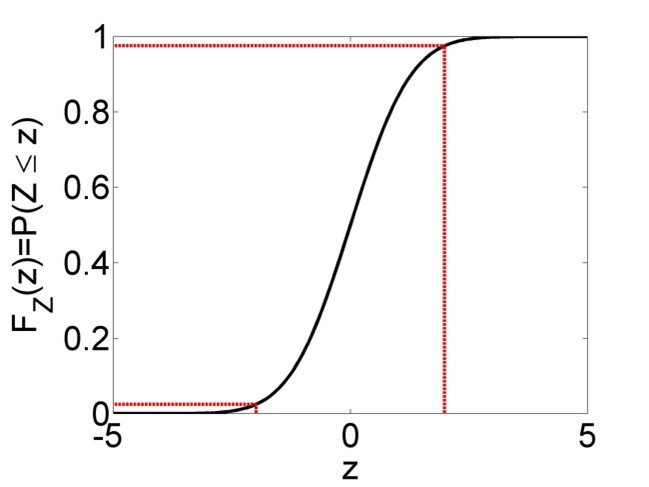
Figure 2.6: Left: Probability density function (PDF) of a t-distributed random variable \(Z\), with central 95% confidence interval marked in red. 95% of the PDF lies between the two bounds, 2.5% lies left of the lower bound and 2.5% right of the upper bound. Right: Cumulative distribution function (CDF) of the same t-distributed random variable \(Z\). The upper bound of the 95% confidence interval is defined as \(t_{n-2;0.975}\), i.e. the 0.975-percentile of the distribution, while the lower bound is defined as \(t_{n-2;0.025}\), which is equivalent to \(-t_{n-2;0.975}\) due to the symmetry of the distribution.
The t-distribution property of the parameter estimates can further be exploited to test each parameter estimate separately for its statistical significance. The significance of the parameter estimates is determined via a t-test. The Null hypothesis is that the true parameters are zero, i.e. the parameter estimates are “not significant”:
\[\begin{equation} H_0:\beta_0=0 \tag{2.28} \end{equation}\] \[\begin{equation} H_0:\beta_1=0 \tag{2.29} \end{equation}\]
This hypothesis is tested against the alternative hypothesis that the true parameters are different from zero, i.e. the parameter estimates are “significant”:
\[\begin{equation} H_1:\beta_0\neq 0 \tag{2.30} \end{equation}\] \[\begin{equation} H_1:\beta_1\neq 0 \tag{2.31} \end{equation}\]
The test statistics are:
\[\begin{equation} t_s=\frac{\hat\beta_0-0}{s_{\hat\beta_0}}\sim t_{n-2} \tag{2.32} \end{equation}\] \[\begin{equation} t_s=\frac{\hat\beta_1-0}{s_{\hat\beta_1}}\sim t_{n-2} \tag{2.33} \end{equation}\]
The “tilde” symbol \((\sim)\) means the test statistics follow a certain distribution, here the t-distribution. This arises again from the regression assumptions noted above. The assumptions are the same as for the common t-test of means, except in the case of linear regression the residuals are assumed iid normal while in the case of means the actual data points \(y\) are assumed iid normal.
Analogous to the common 2-sided t-test, the p-value is defined as:
\[\begin{equation} 2 \cdot \Pr\left(t>|t_s|\right)=2 \cdot \left(1-F_t\left(|t_s|\right)\right) \tag{2.34} \end{equation}\]
The symbol \(F_t\left(|t_s|\right)\) signifies the value of the CDF of the t-distribution at the location of the absolute value of the test statistic (\(|t_s|\), Figure 2.7). With a significance level of say \(\alpha=0.01\) we arrive at critical values of the test statistic \(t_c=t_{n-2;0.99}\) and \(-t_c\) beyond which we reject the Null hypothesis and call the parameter estimates significant (Figure 2.7).
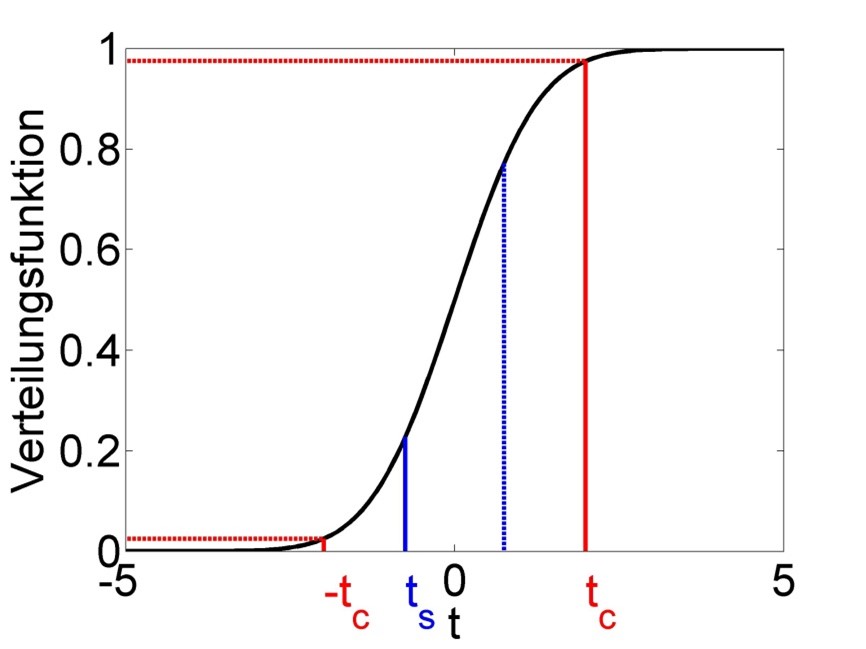
Figure 2.7: Schematic of the t-test of significance of parameter estimates. The test statistic follows a t-distribution under the Null hypothesis. The actual value of the test statistic \(t_s\) is marked in blue and mirrored at zero for the 2-sided test. The critical value of the test statistic \(t_c\), which we get from a significance level of \(\alpha=0.01\), is marked in red; this too is mirrored for the 2-sided test. We reject the Null hypothesis if \(|t_s|>t_c\), i.e. for values of \(t_s\) below \(-t_c\) and above \(t_c\), and then call this parameter estimate significant. We keep the Null hypothesis if \(|t_s|\leq t_c\), i.e. for values of \(t_s\) between \(-t_c\) and \(t_c\), and then call this parameter estimate insignificant (for now). In the example shown the parameter estimate is insignificant.
2.7 Goodness of fit
The final step in regression analysis is assessing the goodness of fit of the linear model. In the first instance this may be done through the coefficient of determination \(\left(r^2\right)\), which is defined as the proportion of variation (in y-direction) that is explained by the model:
\[\begin{equation} r^2=\frac{SSY-SSE}{SSY}=1-\frac{SSE}{SSY} \tag{2.35} \end{equation}\]
As can be seen, when the model fails to explain more variation than the total variation around the mean, i.e. \(SSE=SSY\), then \(r^2=0\). Conversely, when the model fits the data perfectly, i.e. \(SSE=0\), then \(r^2=1\). Any value in between signifies varying levels of goodness of fit. This can be visualised again with Figure 2.4, with the left panel signifying \(SSY\) and the right panel \(SSE\).
When it comes to comparing models of varying complexity (i.e. with more or less parameters) using \(r^2\), then penalising the metric by the number of model parameters makes sense since more complex models (more parameters) automatically lead to better fits, simply due to the greater degrees of freedom that more complex models have for fitting the data. This leads to the adjusted \(r^2\):
\[\begin{equation} \bar r^2=1-\frac{\frac{SSE}{df_{SSE}}}{\frac{SSY}{df_{SSY}}}=1-\frac{SSE}{SSY} \cdot \frac{df_{SSY}}{df_{SSE}} \tag{2.36} \end{equation}\]
The coefficient of determination alone, however, is insufficient for assessing goodness of fit. Consider the four datasets depicted in Figure 2.8, which together form the Anscombe (1973) dataset.
# plot 4 individual datasets
plot(anscombe$x1, anscombe$y1, xlim = c(0, 20), ylim = c(0, 14), pch = 19, type = 'p')
plot(anscombe$x2, anscombe$y2, xlim = c(0, 20), ylim = c(0, 14), pch = 19, type = 'p')
plot(anscombe$x3, anscombe$y3, xlim = c(0, 20), ylim = c(0, 14), pch = 19, type = 'p')
plot(anscombe$x4, anscombe$y4, xlim = c(0, 20), ylim = c(0, 14), pch = 19, type = 'p')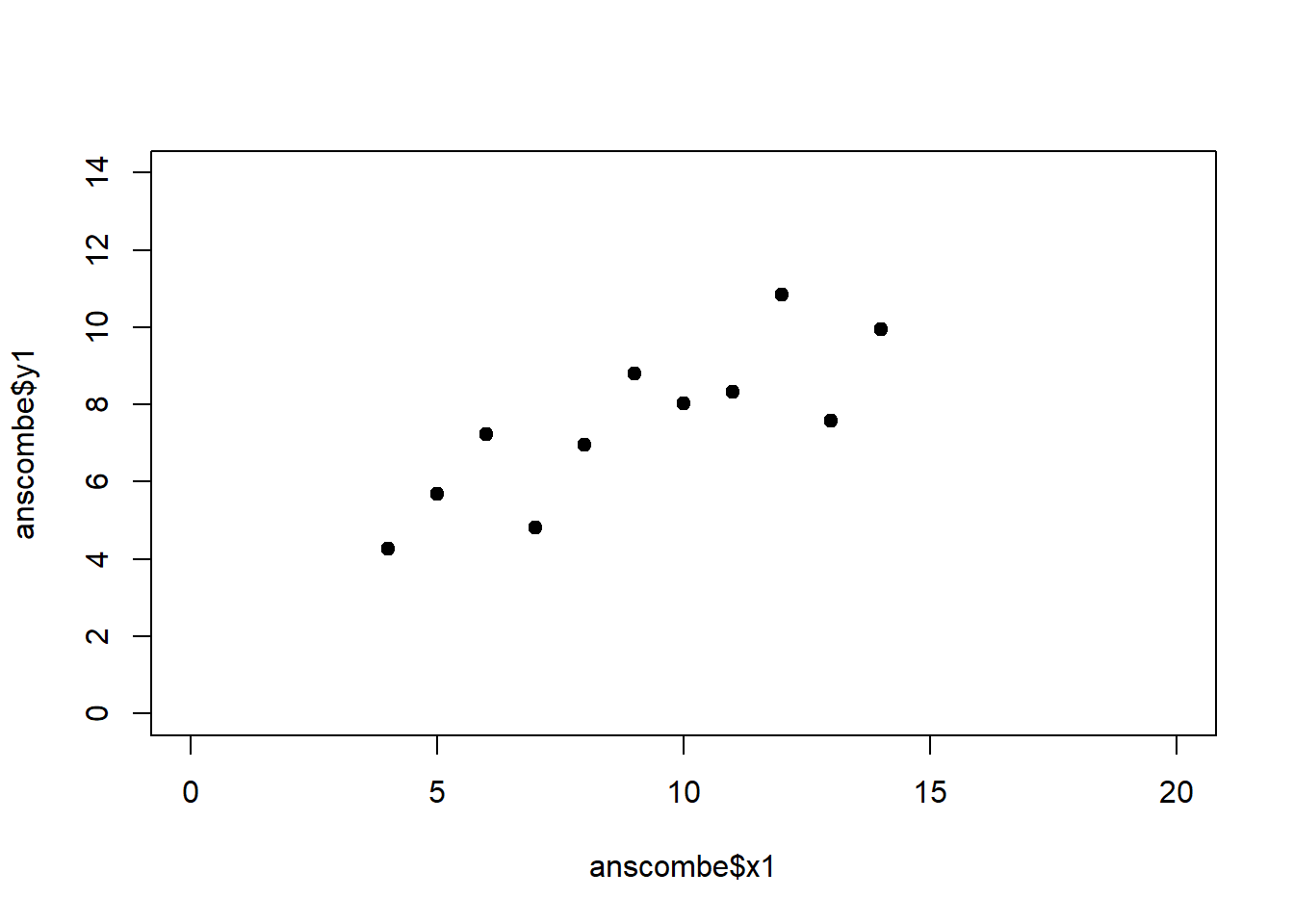
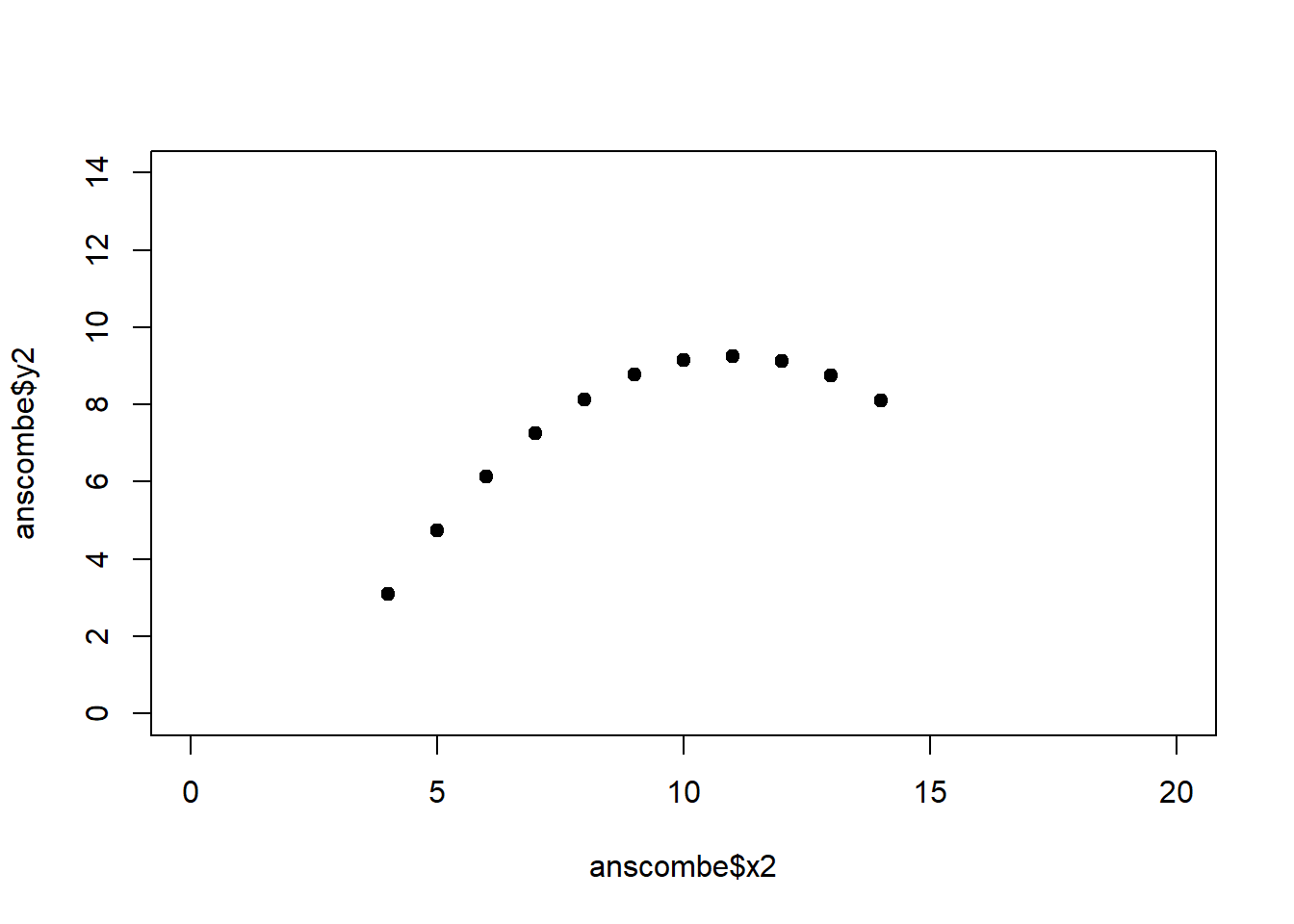
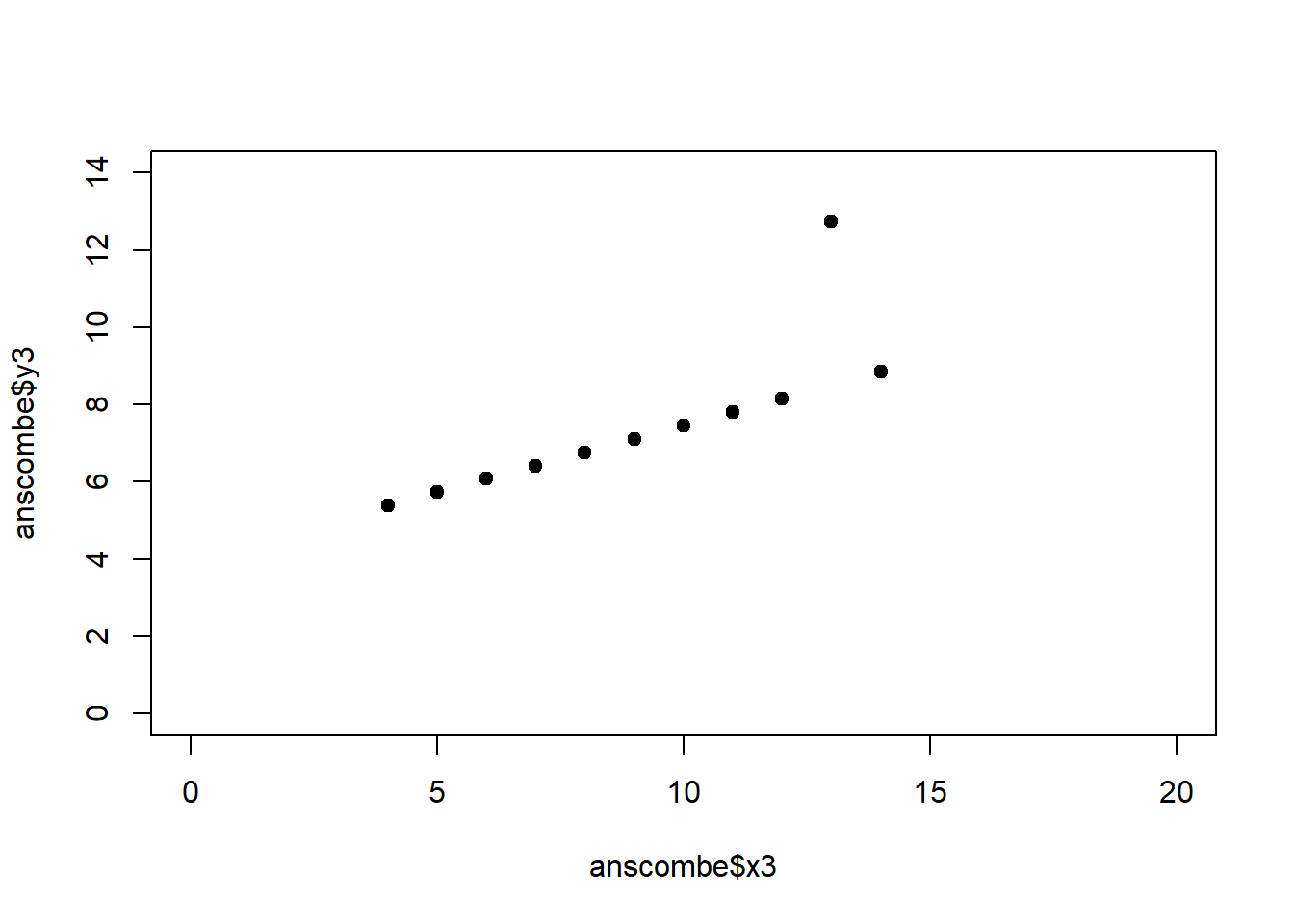
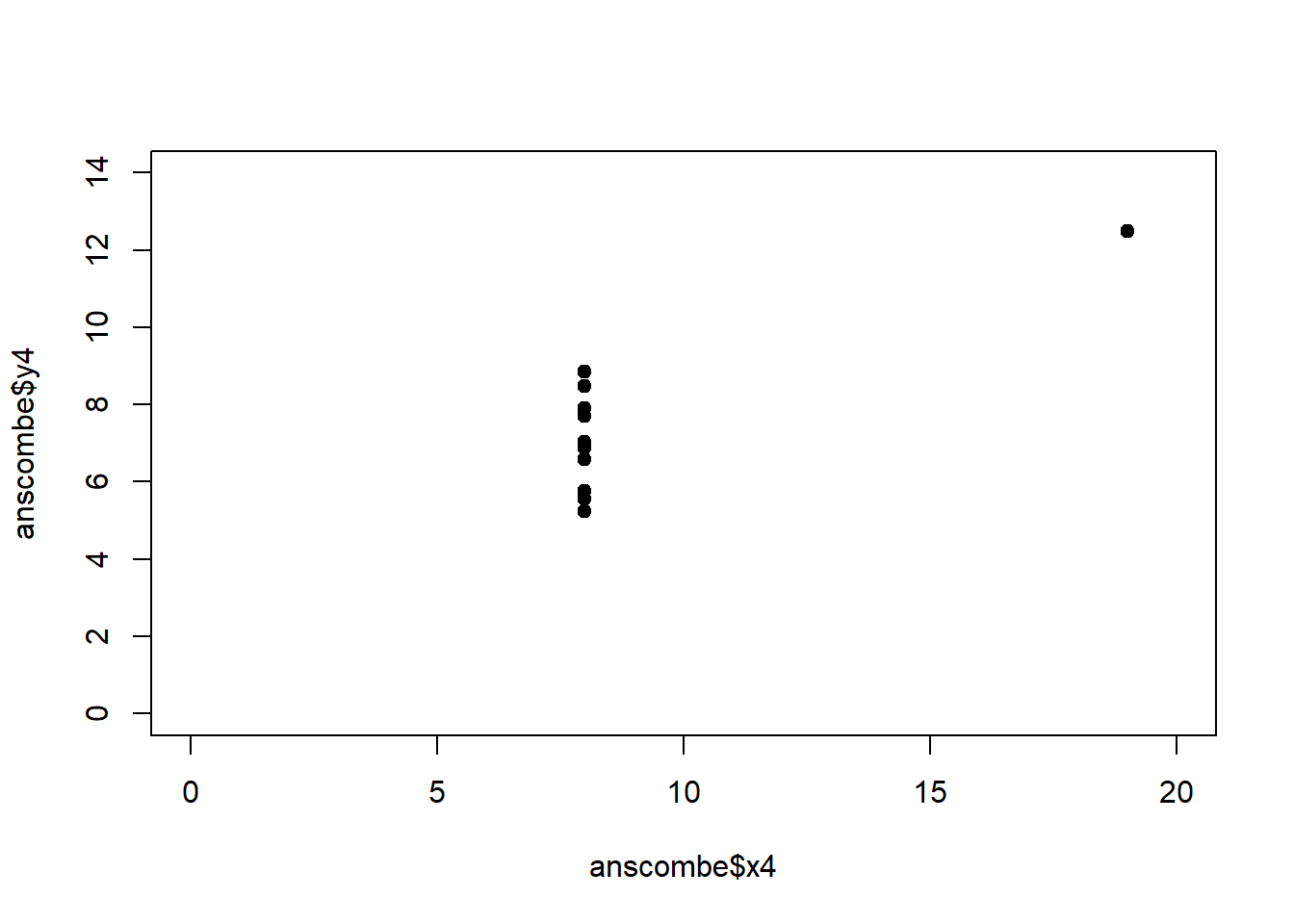
The individual datasets have purposely been constructed to yield virtually the same parameter estimates and coefficients of determination, despite wildly different relationships between \(x\) and \(y\) (Figure 2.9):
# perform individual regressions
fit1 <- lm(y1 ~ x1, data = anscombe)
fit2 <- lm(y2 ~ x2, data = anscombe)
fit3 <- lm(y3 ~ x3, data = anscombe)
fit4 <- lm(y4 ~ x4, data = anscombe)
# extract information about parameter estimates and R2
coef(summary(fit1))## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.0001 1.1247 2.667 0.02573
## x1 0.5001 0.1179 4.241 0.00217## [1] 0.6665## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.001 1.125 2.667 0.025759
## x2 0.500 0.118 4.239 0.002179## [1] 0.6662## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.0025 1.1245 2.670 0.025619
## x3 0.4997 0.1179 4.239 0.002176## [1] 0.6663## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.0017 1.1239 2.671 0.025590
## x4 0.4999 0.1178 4.243 0.002165## [1] 0.6667In these summary tables, “(Intercept)” stands for \(\beta_0\), while “x1” to “x4” stand for \(\beta_1\). The column “Estimate” gives \(\hat\beta_0\) and \(\hat\beta_1\), the column “Std. Error” gives \(s_{\hat\beta_0}\) and \(s_{\hat\beta_1}\), the column “t value” gives the individual \(t_s\) and the column “Pr(>|t|)” gives the respective p-value.
# plot individual datasets with regression lines
plot(anscombe$x1, anscombe$y1, xlim = c(0, 20), ylim = c(0, 14), pch = 19, type = 'p')
abline(coef(fit1), lwd = 3, col = "red")
plot(anscombe$x2, anscombe$y2, xlim = c(0, 20), ylim = c(0, 14), pch = 19, type = 'p')
abline(coef(fit2), lwd = 3, col = "red")
plot(anscombe$x3, anscombe$y3, xlim = c(0, 20), ylim = c(0, 14), pch = 19, type = 'p')
abline(coef(fit3), lwd = 3, col = "red")
plot(anscombe$x4, anscombe$y4, xlim = c(0, 20), ylim = c(0, 14), pch = 19, type = 'p')
abline(coef(fit4), lwd = 3, col = "red")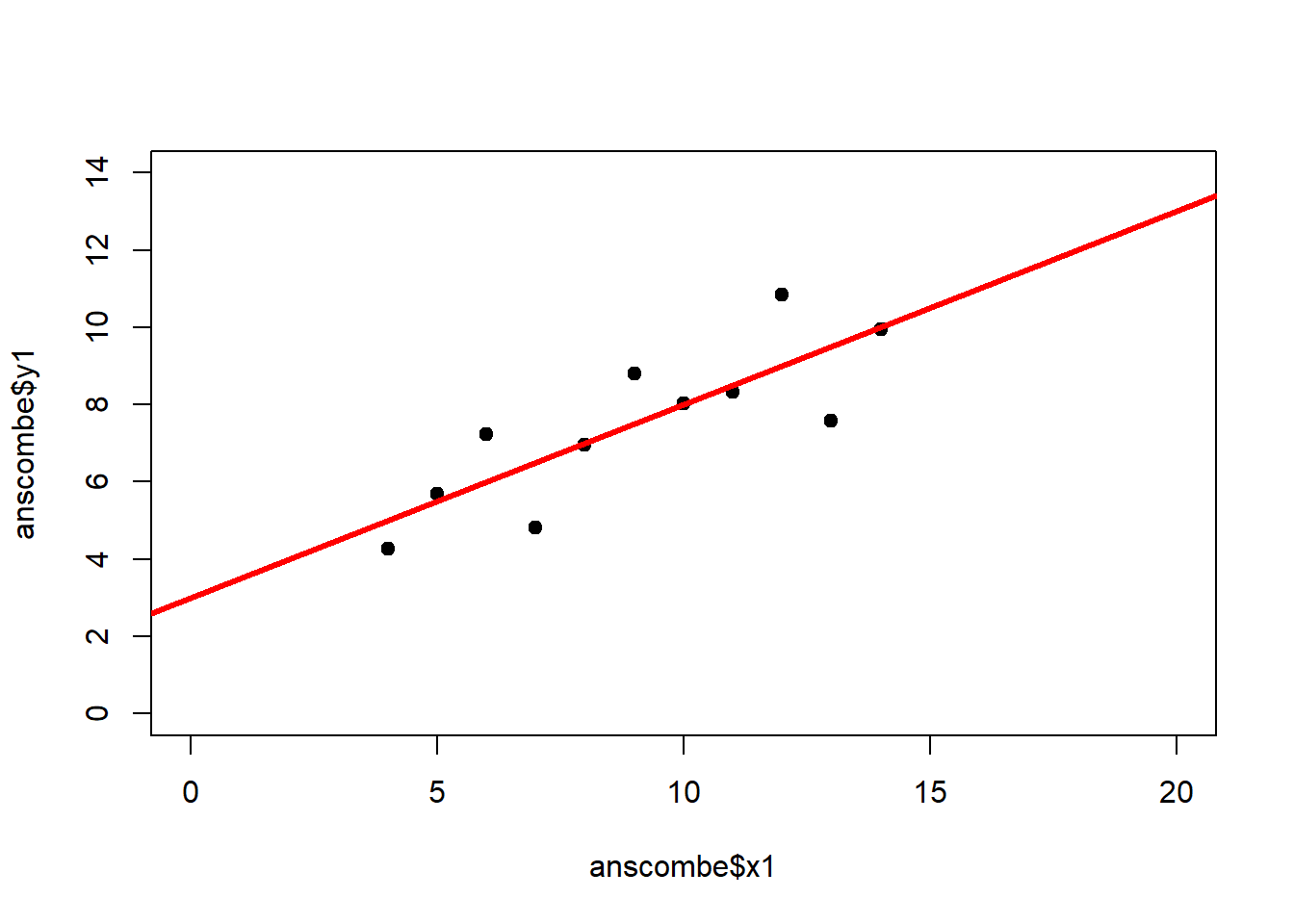
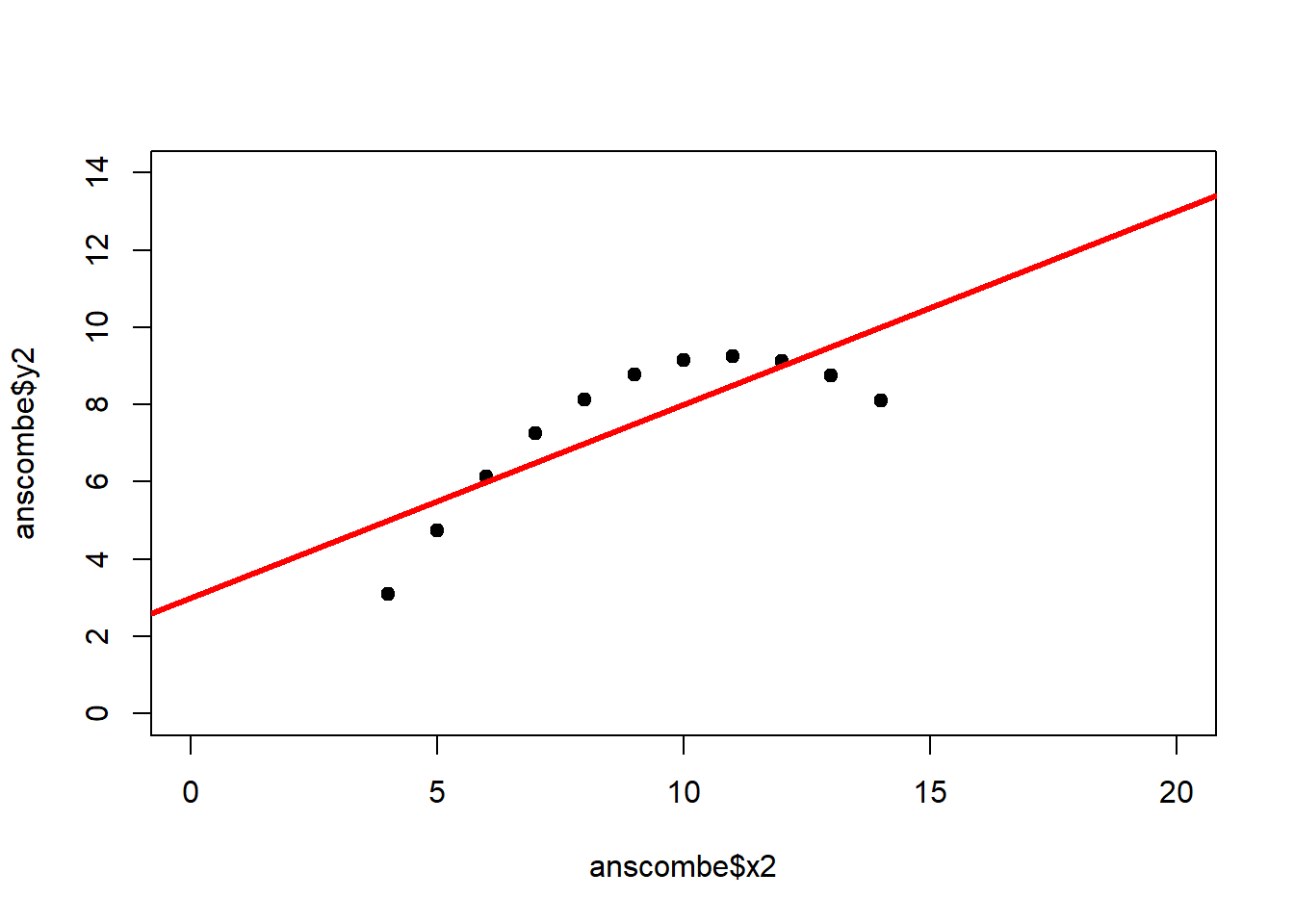
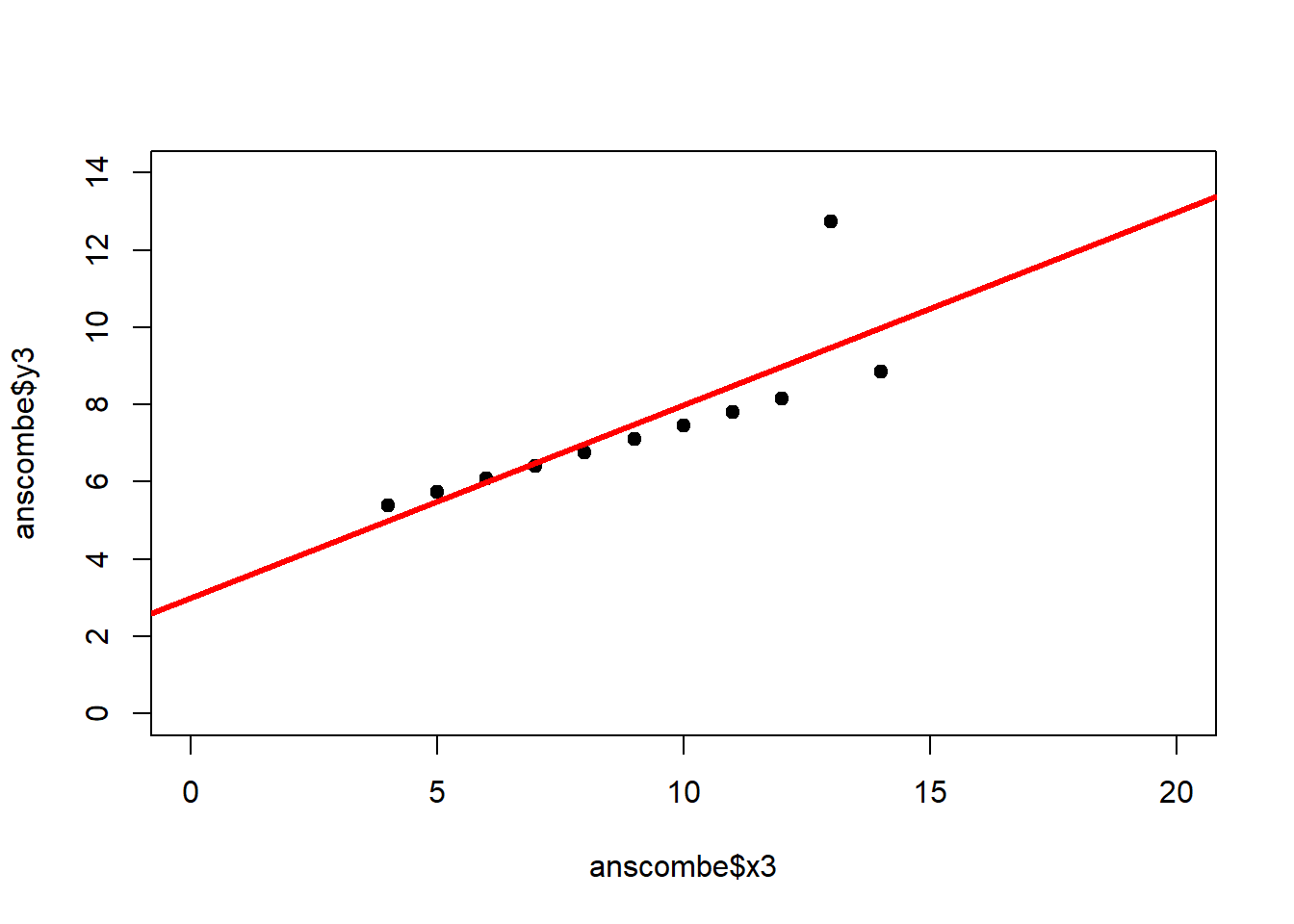
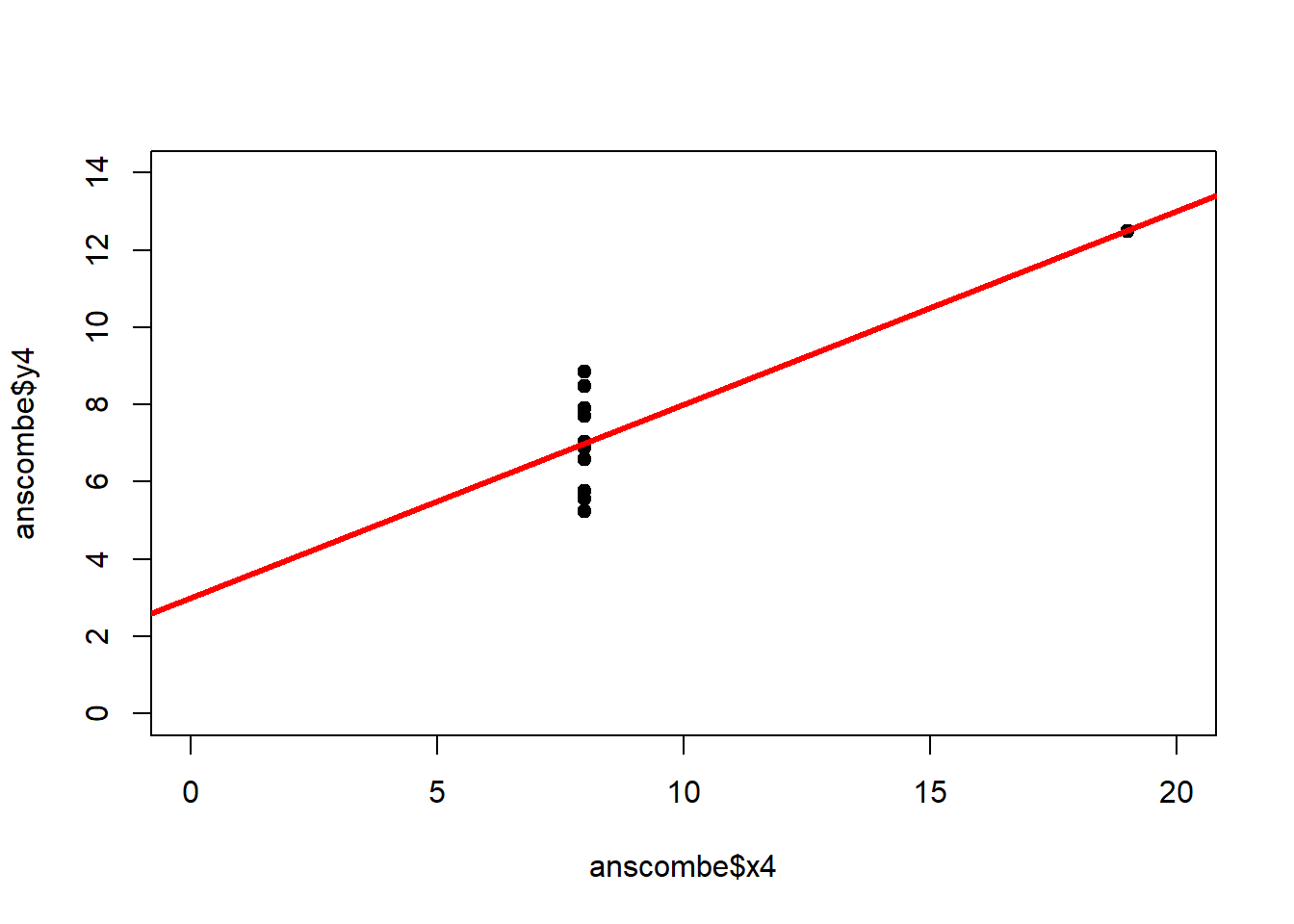
Figure 2.9: Regression analysis of the four Anscombe (1973) datasets, yielding virtually the same parameter estimates and coefficients of determination (see above), despite wildly different relationships between \(x\) and \(y\).
The coefficient of determination is insensitive to these and similar systematic deviations from the regression line. But we can detect these deficiencies of the model by looking at plots like Figure 2.9, and more generally by performing residual diagnostics that check model assumptions.
The fundamental assumptions of linear regression are:
- The residuals are independent, in which case there will be no serial correlation in the residual plot – this can be tested using the Durbin-Watson test
- The residuals are normally distributed – this can be visually assessed using the quantile-quantile plot (QQ plot) and the residual histogram, and can be tested using the Kolmogorov-Smirnov test and the Shapiro-Wilk test
- The variance is the same across residuals, i.e. residuals are homoscedastic, in which case there is no “fanning out” of the residuals
If these assumptions are not met then we can resort to data transformation, weighted regression or Generalised Linear Models, which we will cover in chapter 6.
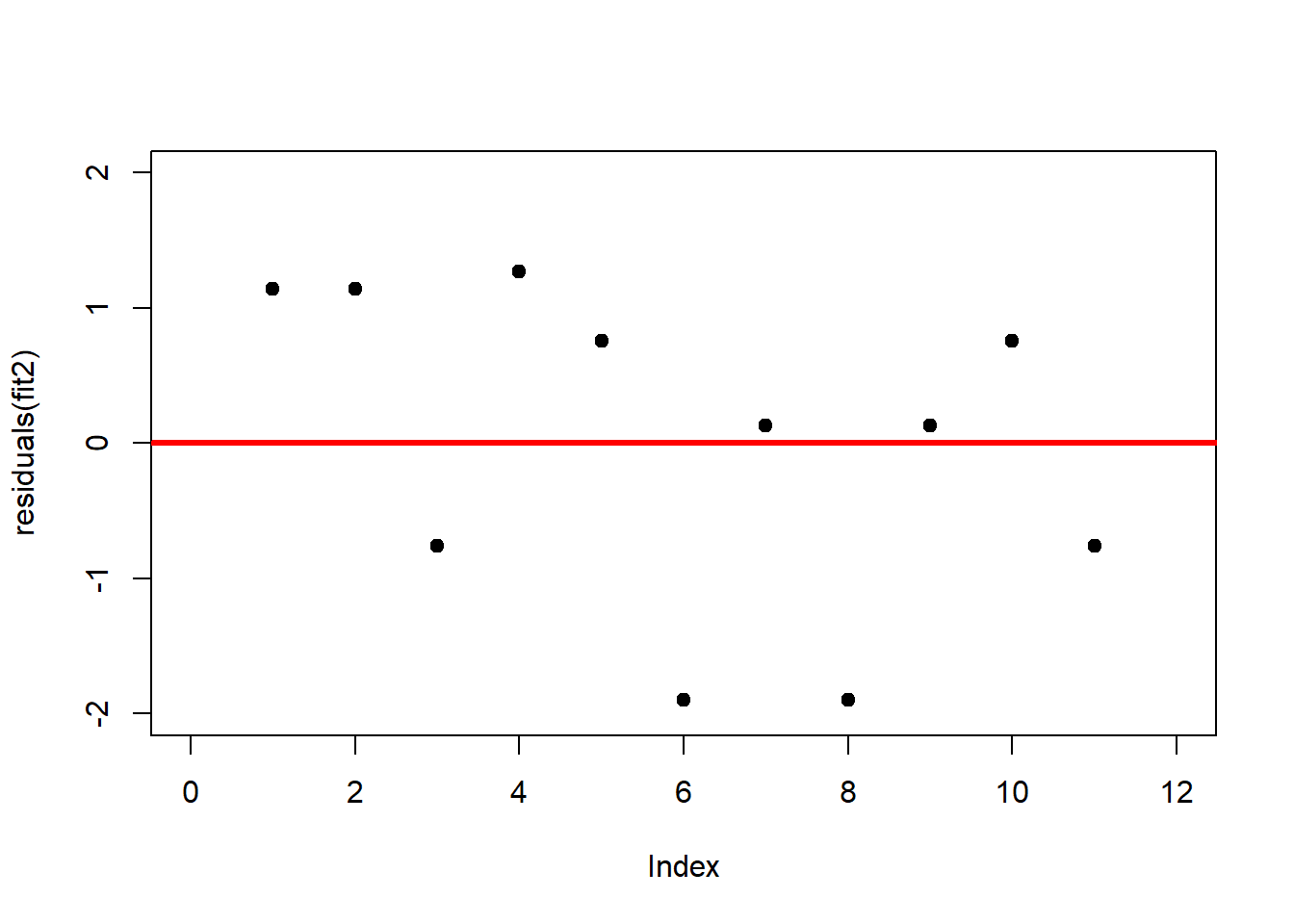
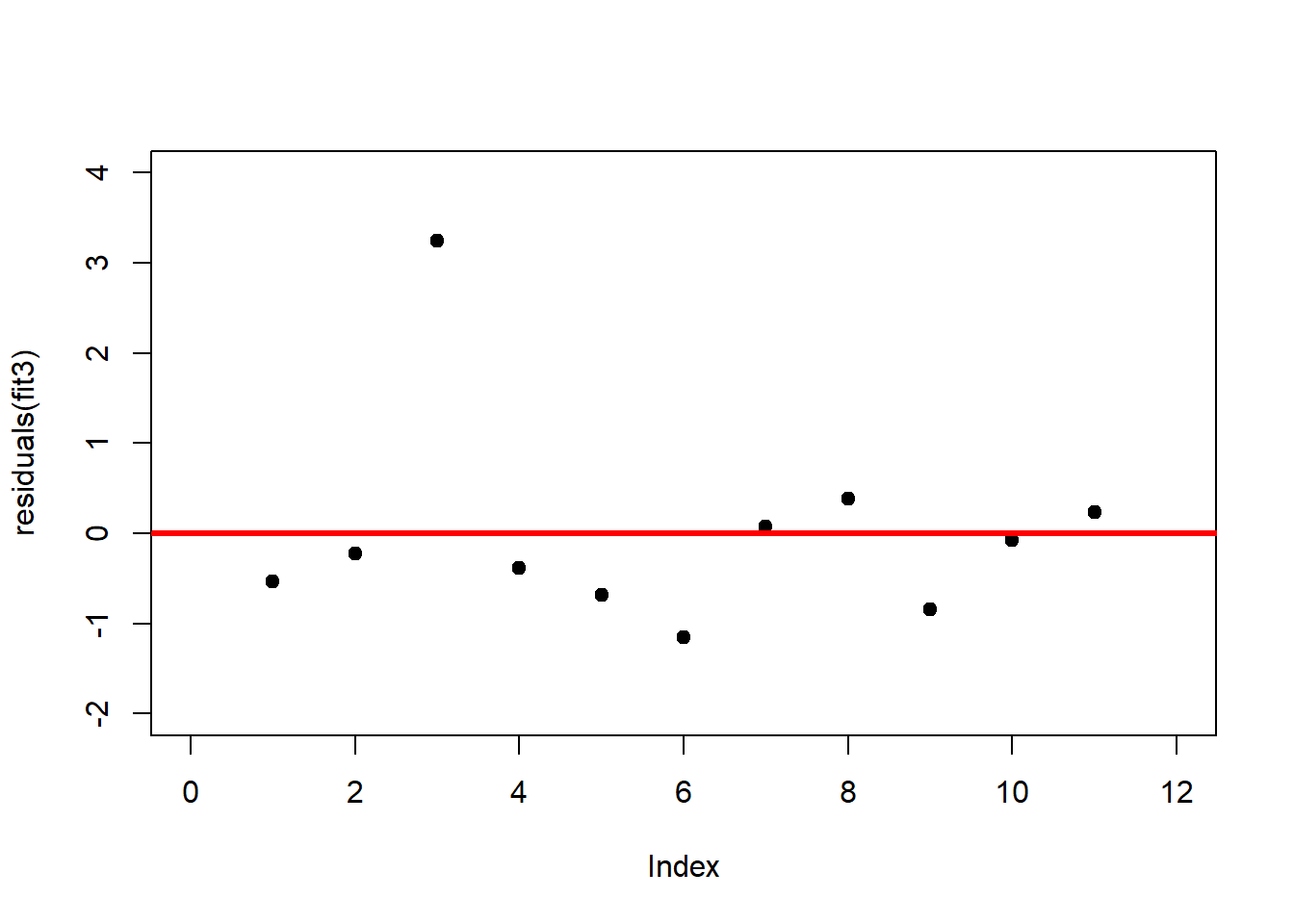
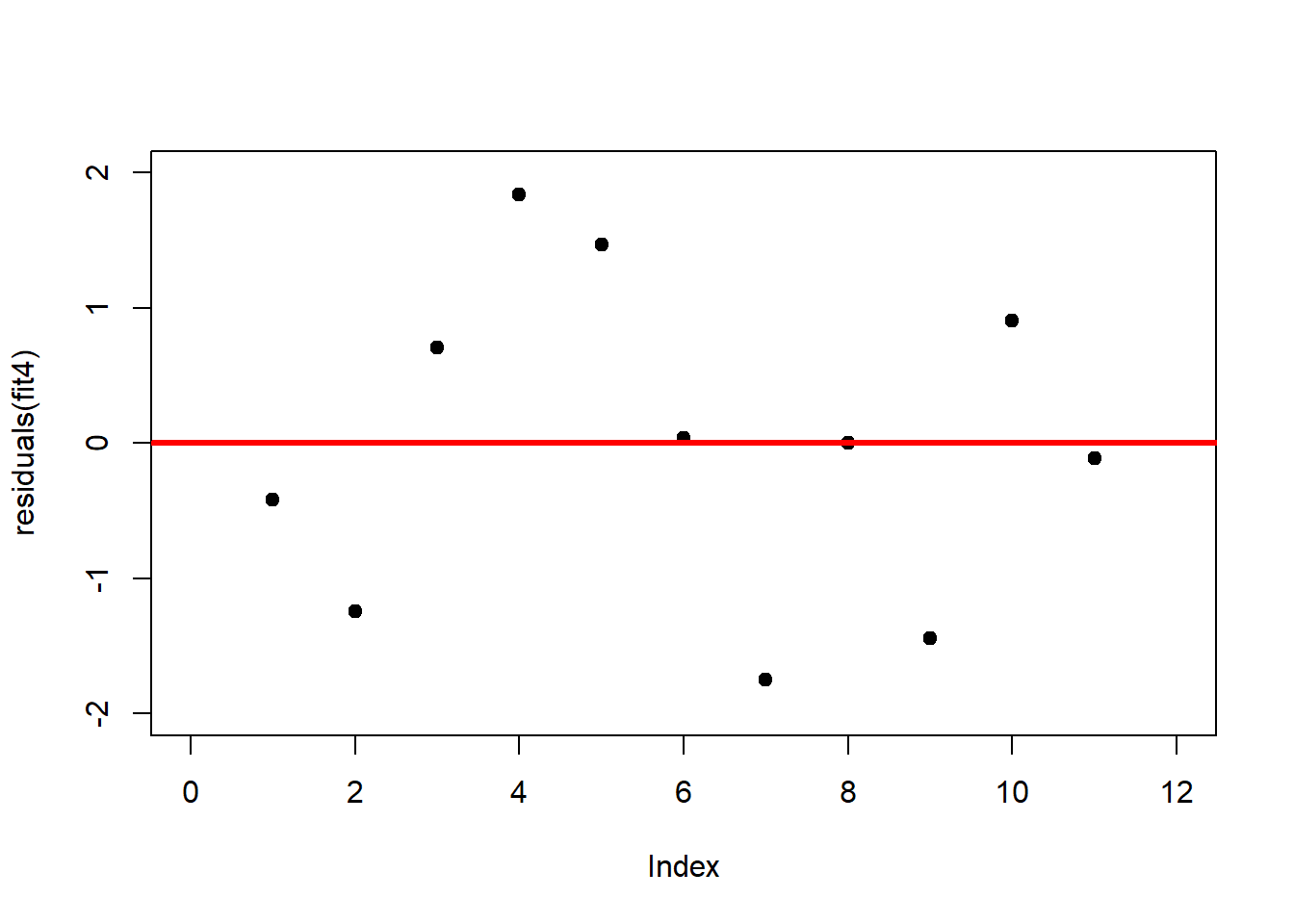
A first useful diagnostic plot is of the residuals in series, i.e. by index \(i\), to see if there is a pattern due to the data collection process (Figure 2.10). For the Anscombe dataset, this detects the nonlinearity in dataset 2 (top-right) and the outlier in dataset 3 (bottom-left), compare Figure 2.9.
# plot residuals against index
plot(residuals(fit1), xlim = c(0, 12), ylim = c(-2, 2), pch = 19, type = 'p')
abline(h = 0, lwd = 3, col = "red")
plot(residuals(fit2), xlim = c(0, 12), ylim = c(-2, 2), pch = 19, type = 'p')
abline(h = 0, lwd = 3, col = "red")
plot(residuals(fit3), xlim = c(0, 12), ylim = c(-2, 4), pch = 19, type = 'p')
abline(h = 0, lwd = 3, col = "red")
plot(residuals(fit4), xlim = c(0, 12), ylim = c(-2, 2), pch = 19, type = 'p')
abline(h = 0, lwd = 3, col = "red")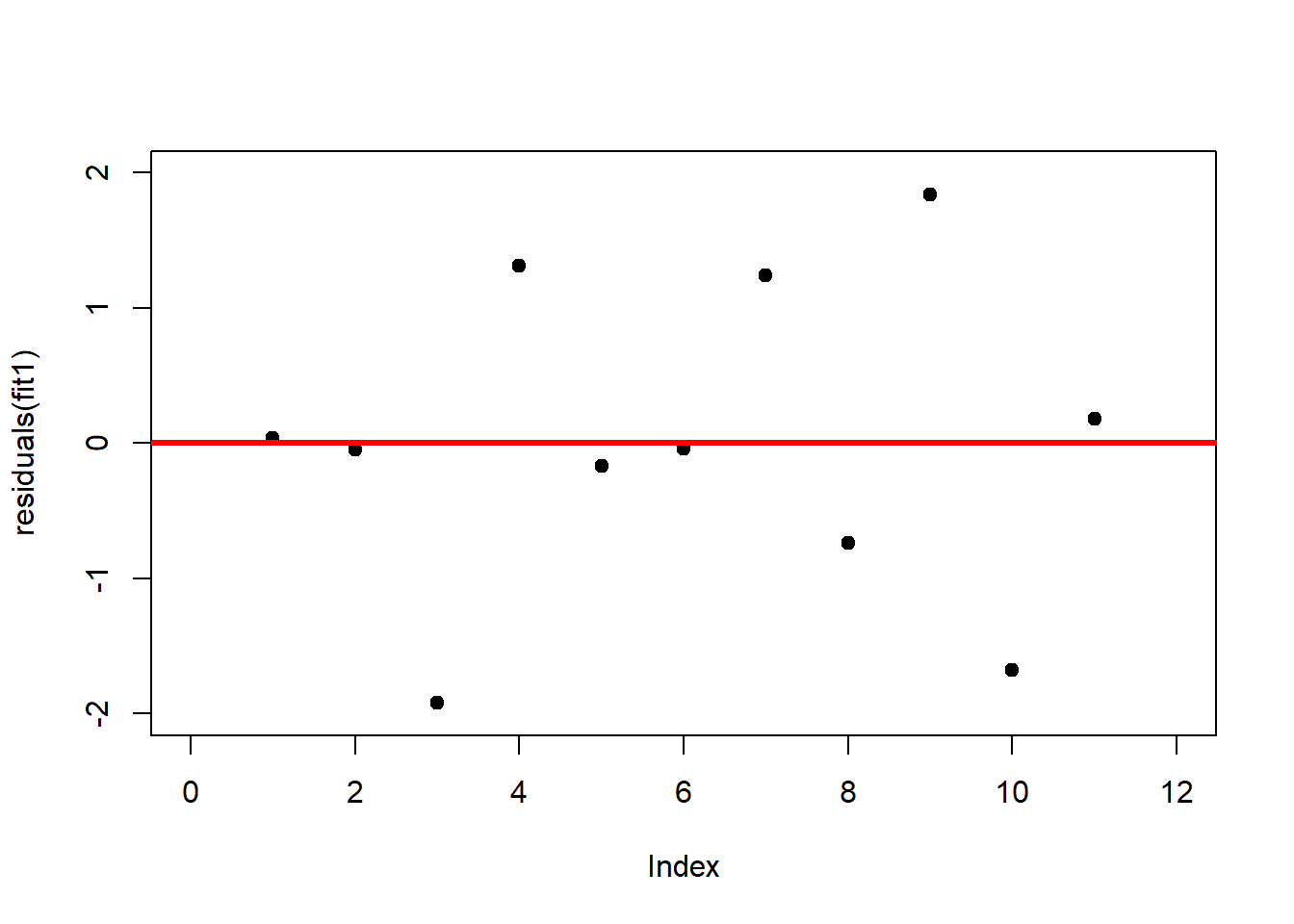
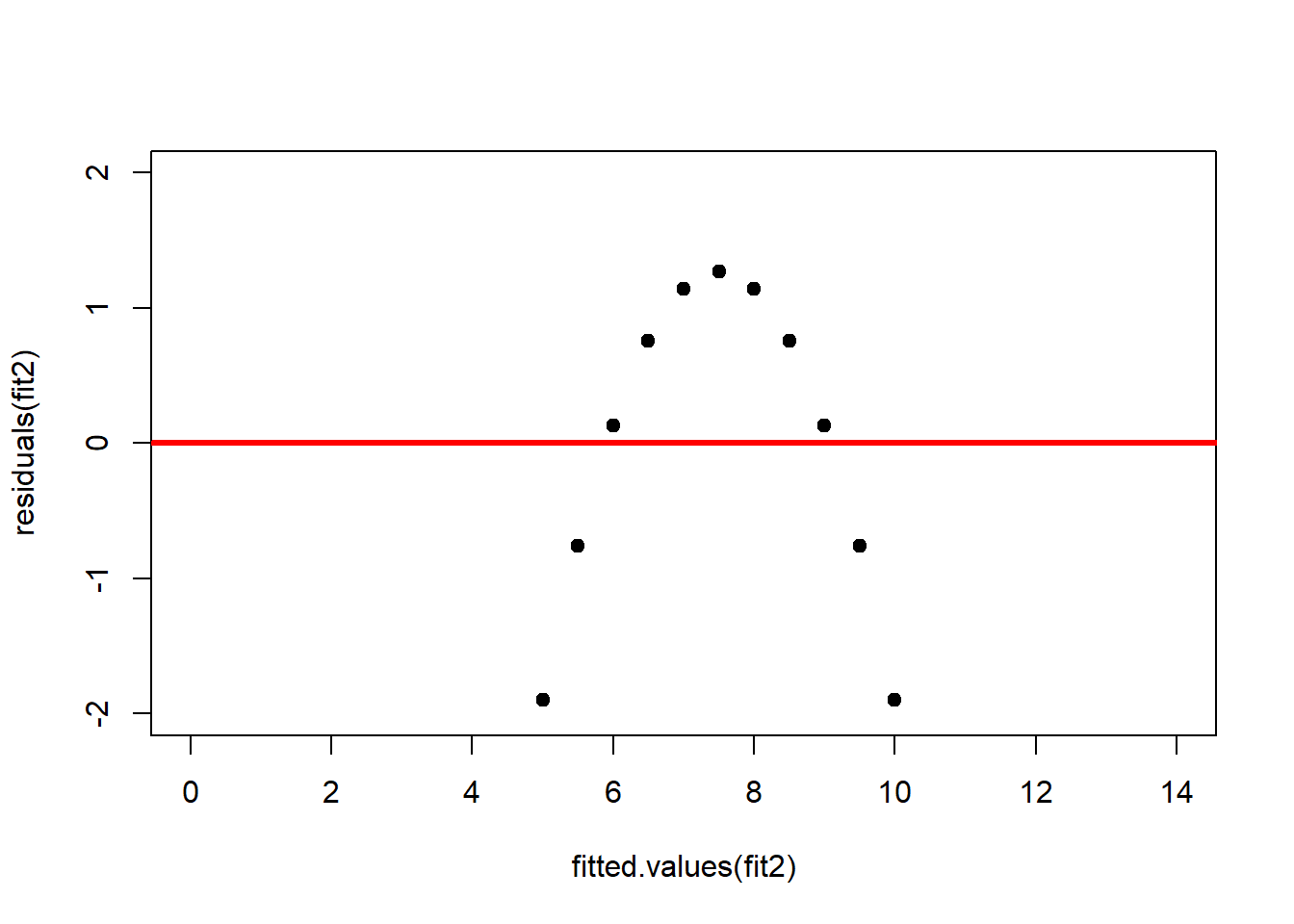
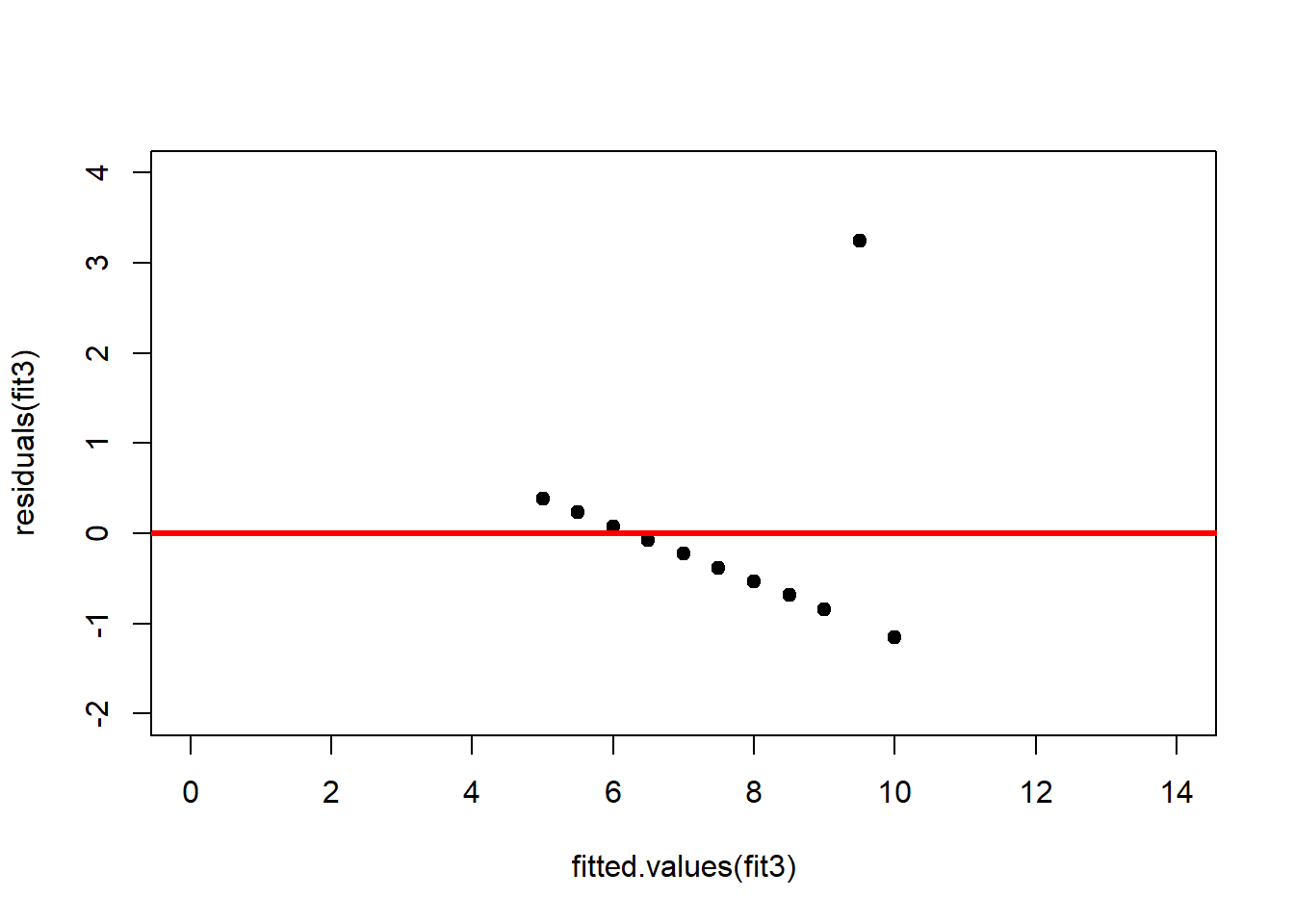
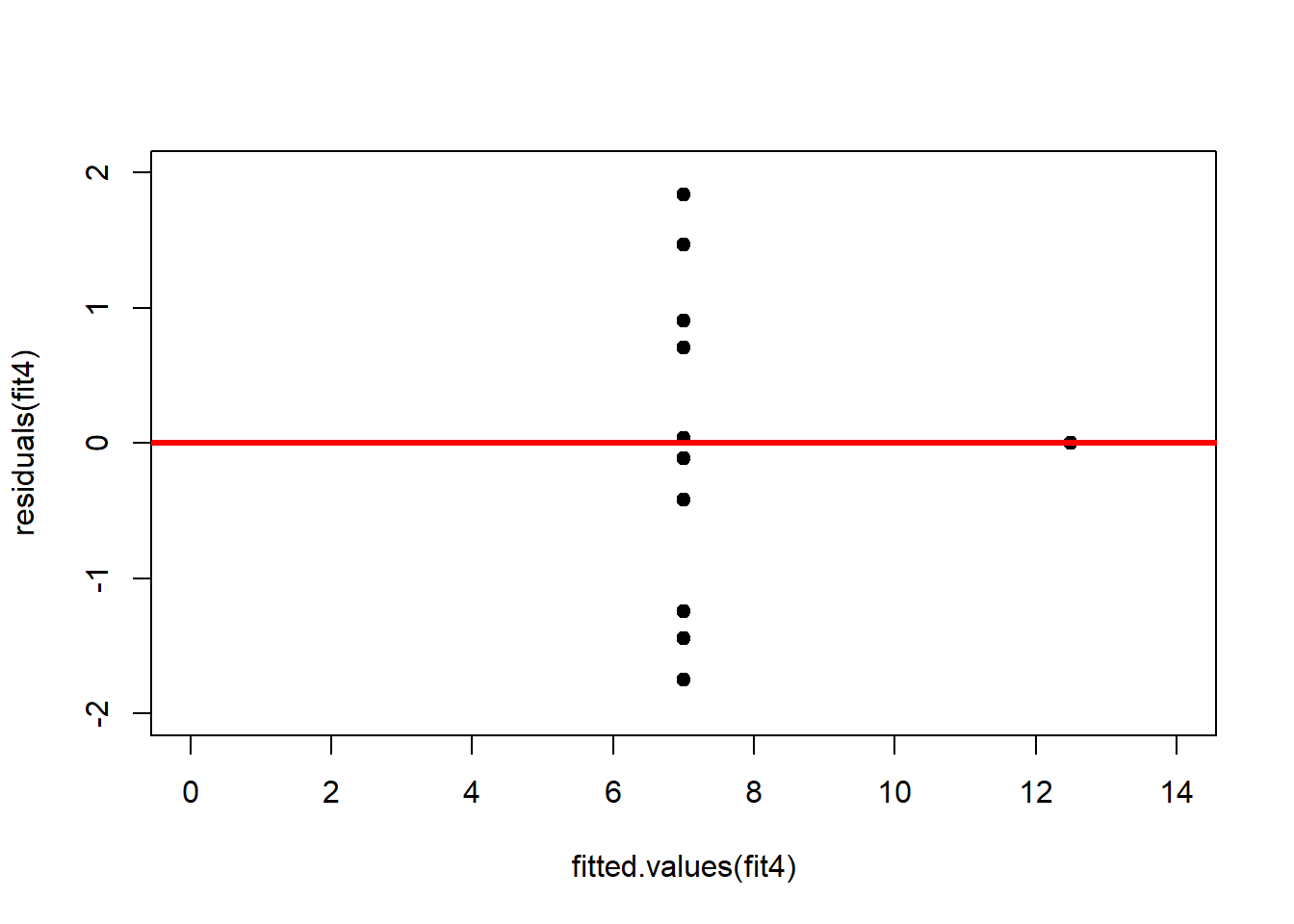
We should also plot the residuals by predicted value of \(y\) to see if there is a pattern as a function of magnitude (Figure 2.11). For the Anscombe dataset, this emphasizes the non-linearity of dataset 2 (top-right) and the outlier in dataset 3 (bottom-left) and also detects the singular extreme point in dataset 4 (bottom-right). In sum, the independence and homoscedasticity assumptions seem to be violated in all datasets except dataset 1. This would have to be formally tested using the Durbin-Watson test, for example.
# plot residuals against predicted value of y
plot(fitted.values(fit1),residuals(fit1), xlim = c(0, 14), ylim = c(-2, 2), pch = 19, type = 'p')
abline(h = 0, lwd = 3, col = "red")
plot(fitted.values(fit2),residuals(fit2), xlim = c(0, 14), ylim = c(-2, 2), pch = 19, type = 'p')
abline(h = 0, lwd = 3, col = "red")
plot(fitted.values(fit3),residuals(fit3), xlim = c(0, 14), ylim = c(-2, 4), pch = 19, type = 'p')
abline(h = 0, lwd = 3, col = "red")
plot(fitted.values(fit4),residuals(fit4), xlim = c(0, 14), ylim = c(-2, 2), pch = 19, type = 'p')
abline(h = 0, lwd = 3, col = "red")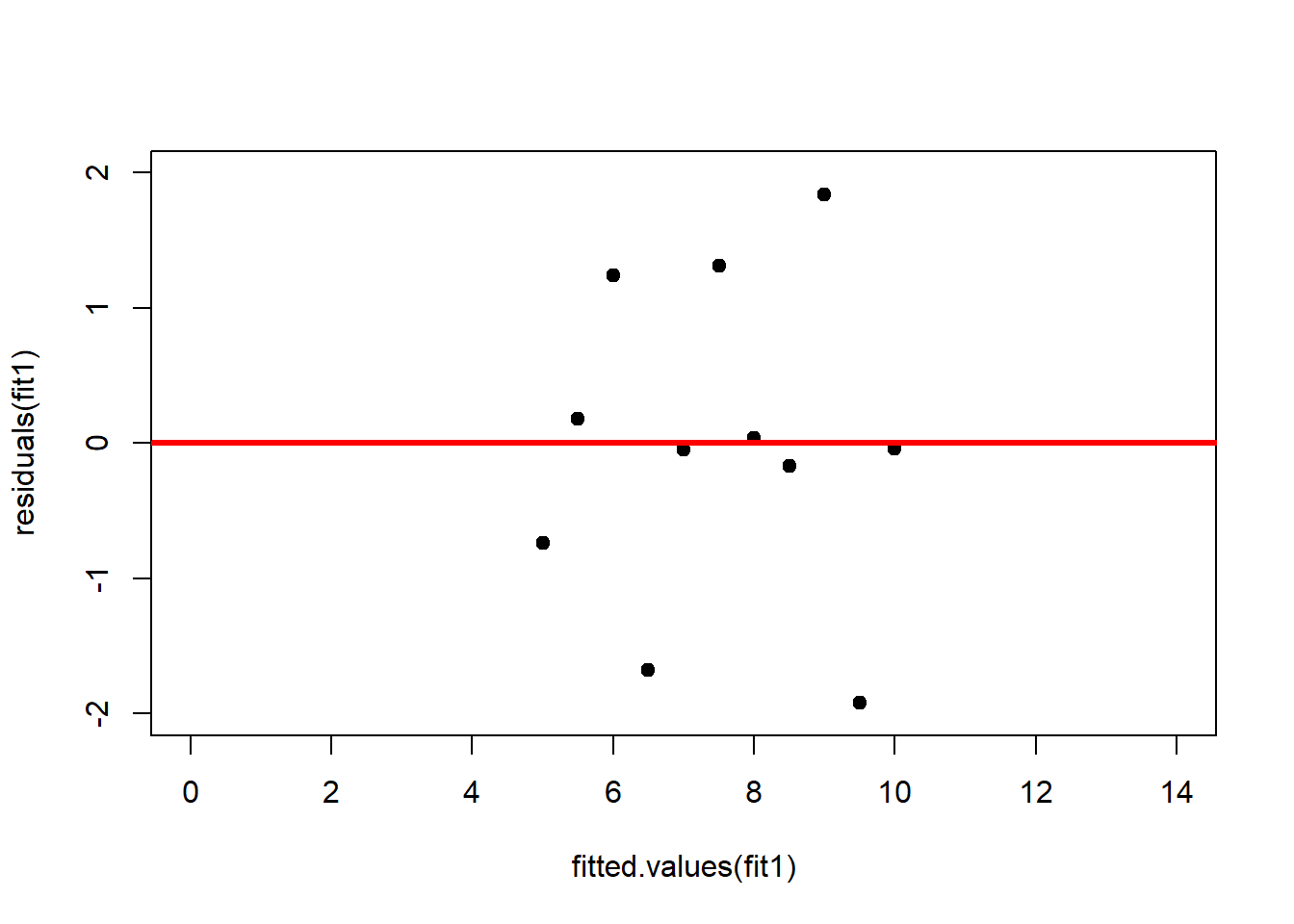
The normality assumption can be assessed using the QQ plot (Figure 2.12).
# QQ plots
qqnorm(residuals(fit1), xlim = c(-4, 4), ylim = c(-4, 4))
qqline(residuals(fit1))
qqnorm(residuals(fit2), xlim = c(-4, 4), ylim = c(-4, 4))
qqline(residuals(fit2))
qqnorm(residuals(fit3), xlim = c(-4, 4), ylim = c(-4, 4))
qqline(residuals(fit3))
qqnorm(residuals(fit4), xlim = c(-4, 4), ylim = c(-4, 4))
qqline(residuals(fit4))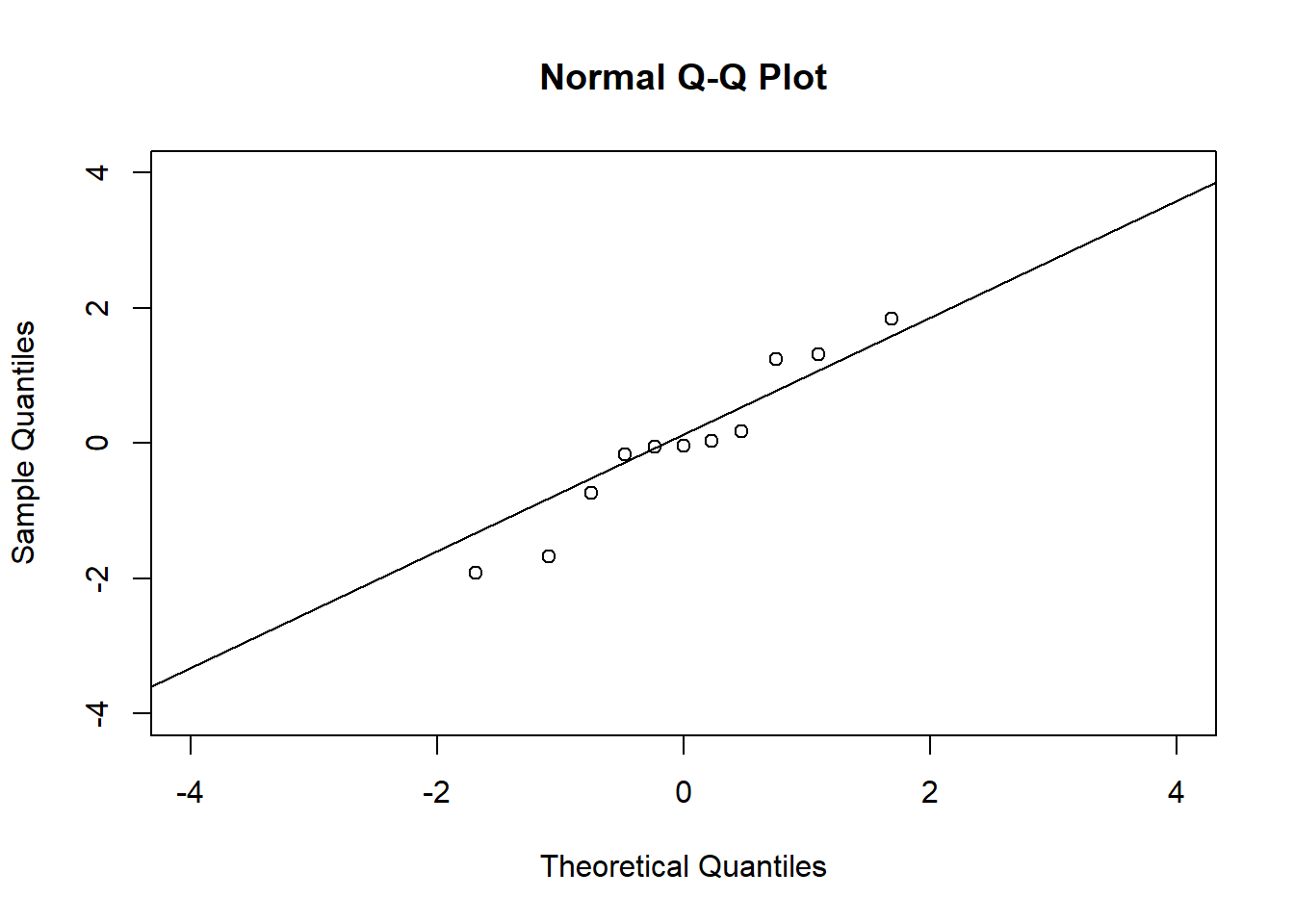
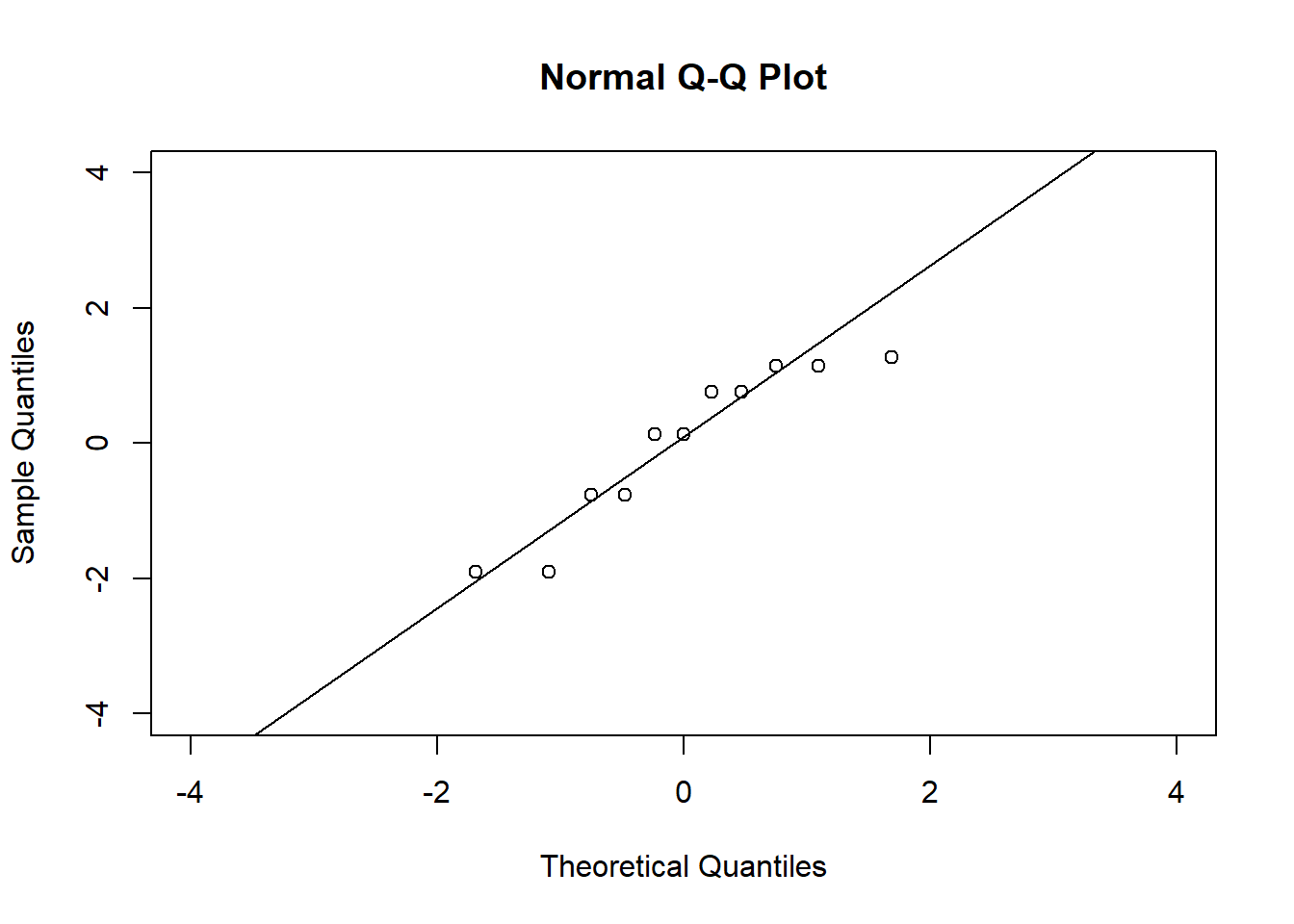
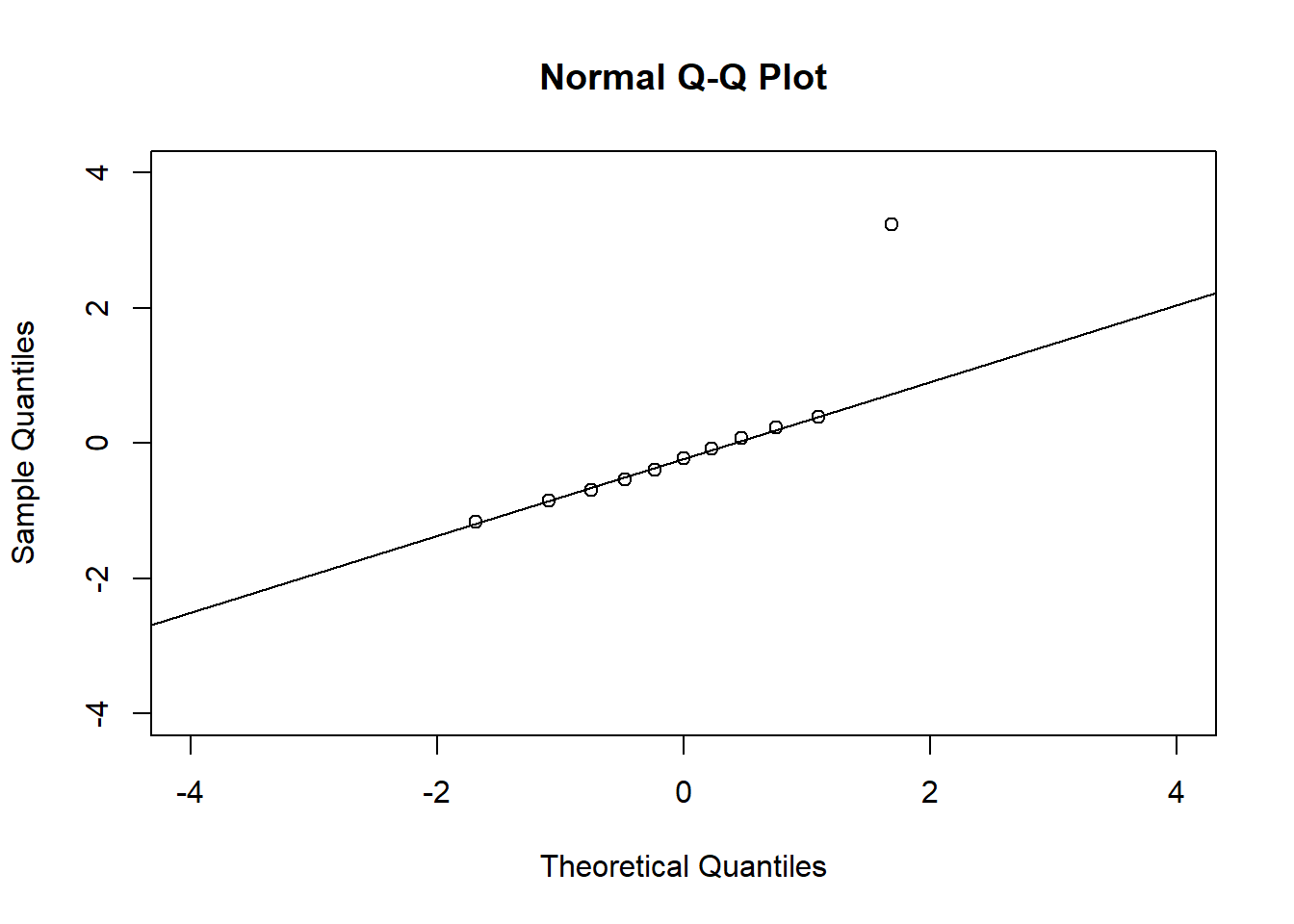
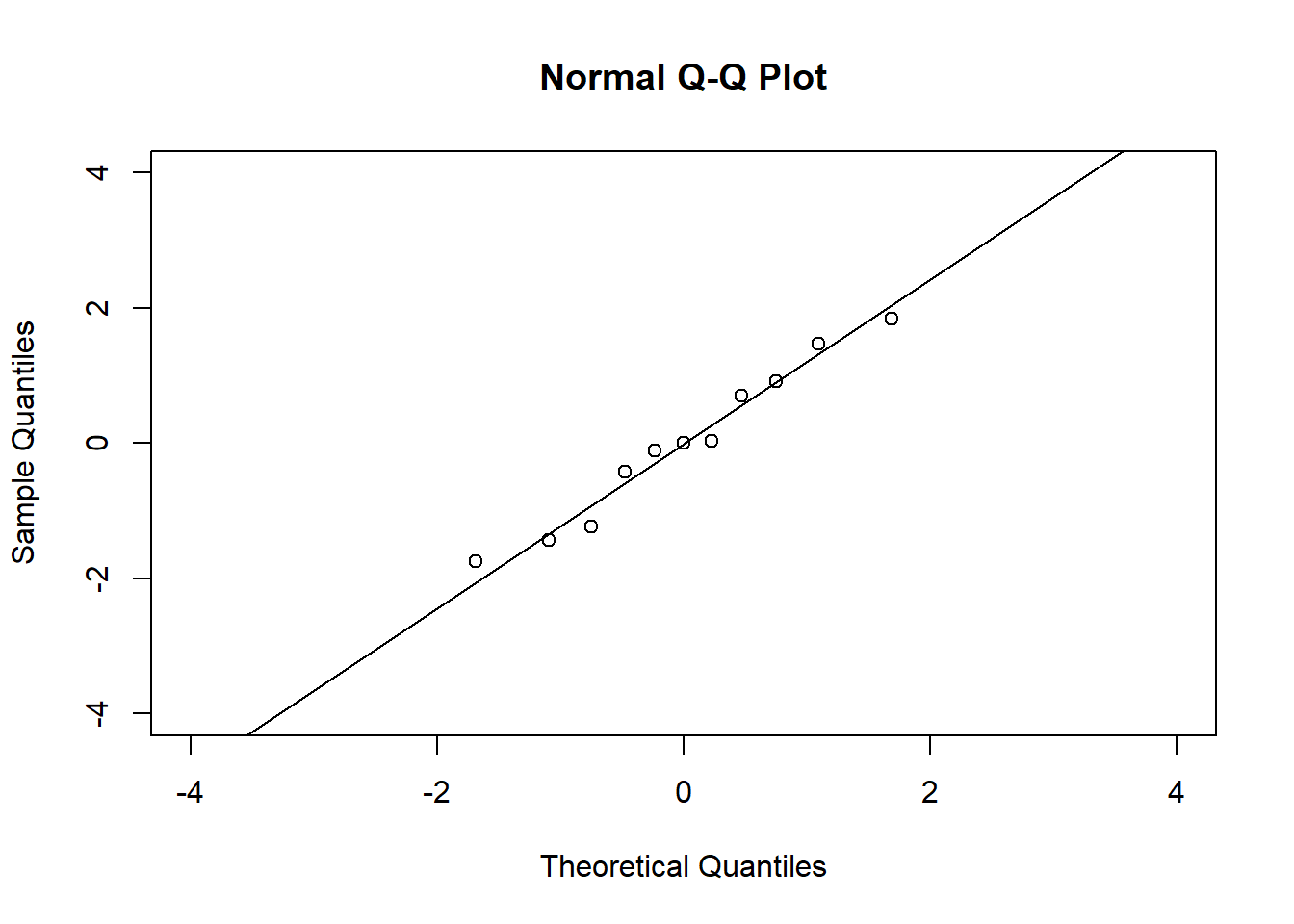
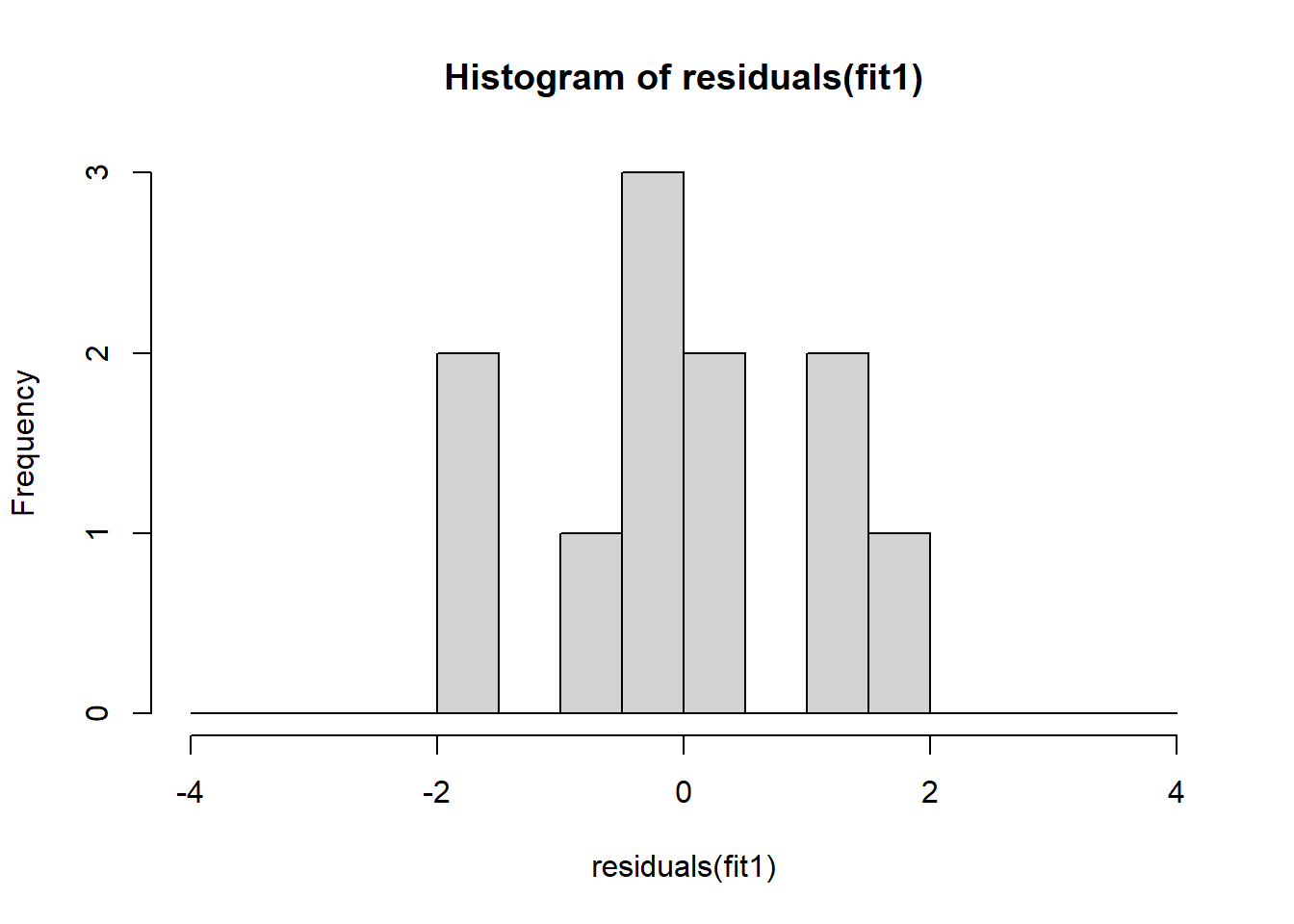
In the QQ plot, every data point represents a certain quantile of the empirical distribution. This quantile (after standardisation) is plotted (vertical axis) against the value of that quantile expected under a standard normal distribution (horizontal axis). The resultant shapes say something about the distribution of the residuals. You can explore possible shapes using this QQ plot app. In case of a normal distribution, the residuals all fall on a straight line. In the Anscombe dataset, the only clearly non-normal dataset seems to be #3 (bottom-left). This would have to be formally tested using the Kolmogorov-Smirnov test or the Shapiro-Wilk test, for example.
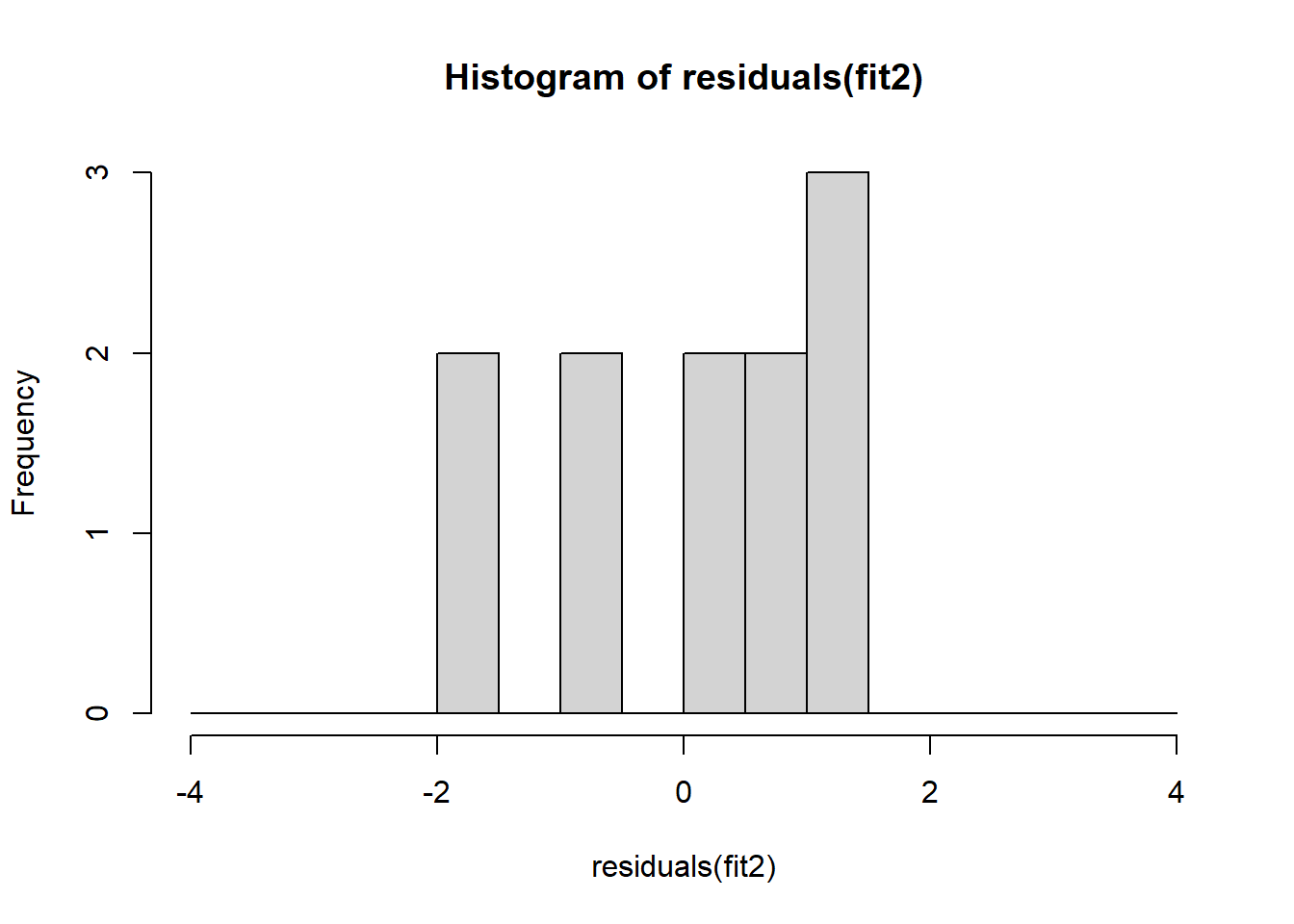
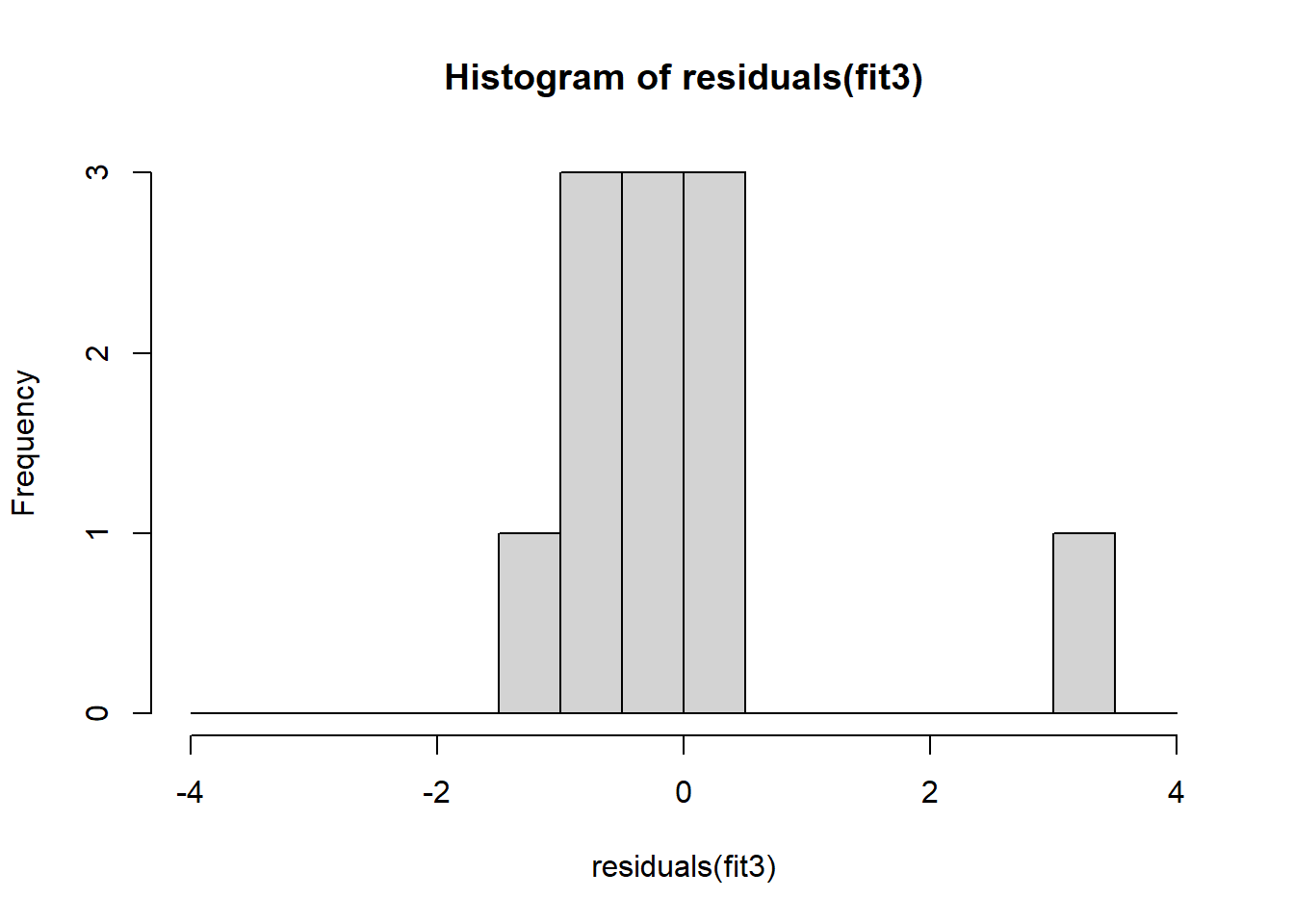
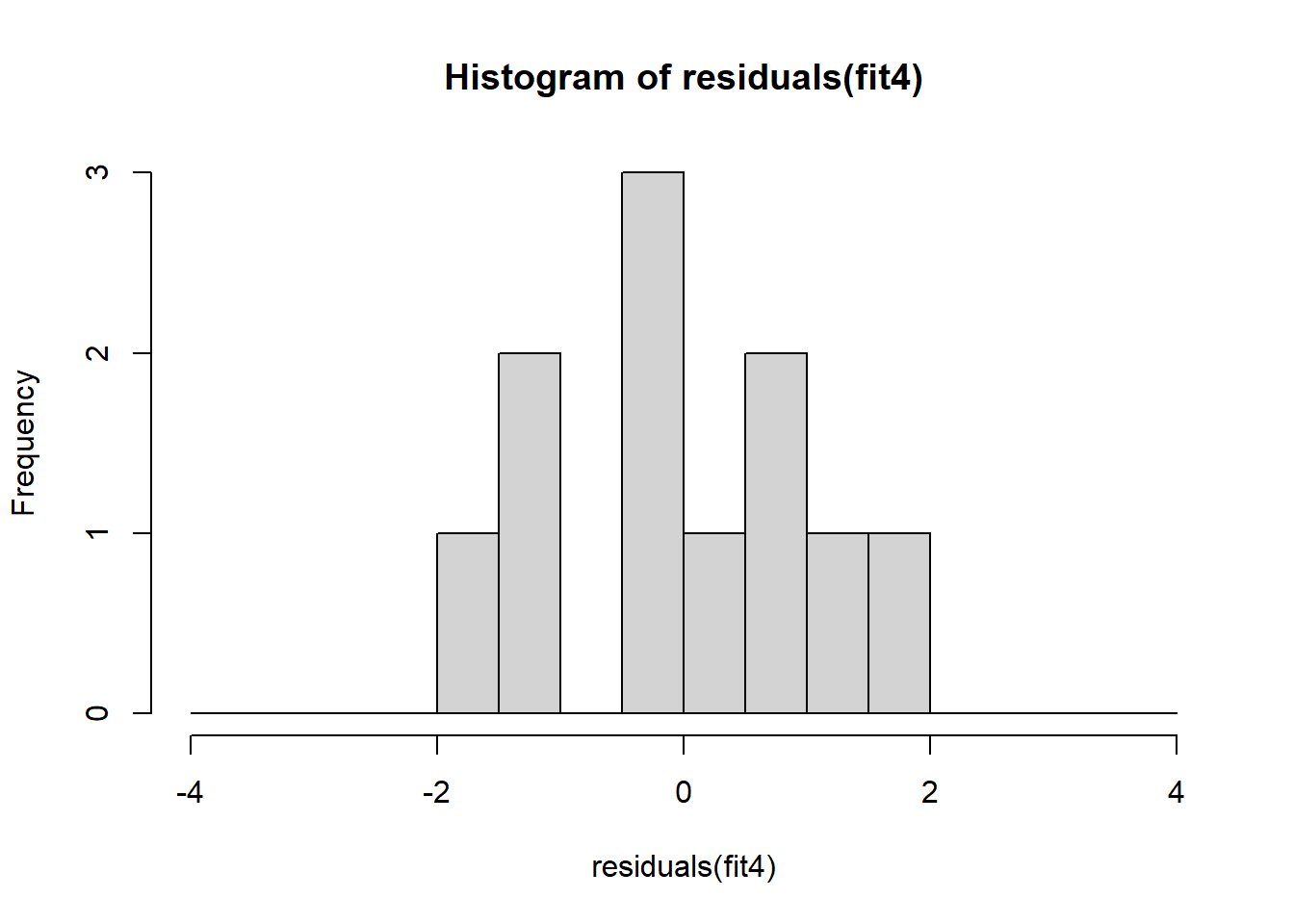
The non-normality of dataset 3 becomes apparent also in the residual histograms (Figure 2.13). They also emphasize the outlier in dataset 3. Note, it is generally difficult to reject the hypothesis of normally distributed residuals with so few data points.
References
The answer can be found at the end of this script.↩︎
Note, we here follow a classical statistical exposition bearing in mind that the concept of significance is not very useful and potentially dangerous (Amrhein et al. 2019). Still, p-values can be used to judge whether results are compatible with unimportant effects.↩︎