Kapitel 3 Häufigkeiten und Lageparameter
Mit diesem Kapitel des Skriptes steigen wir in die deskriptive Statistik ein. Lesen Sie hierzu bitte Kapitel 3.2.1 und 3.2.2 von Zimmermann-Janschitz (2014). Im Folgenden finden Sie wie gehabt Ergänzungen zu diesen Kapiteln.
3.1 Ziel der deskriptiven Statistik
Jene Eigenschaft eines Untersuchungselements, die für die statistische Untersuchung von Bedeutung ist, wird als Merkmal \(X\) des Elements bezeichnet. Der Merkmalswert \(x_i\) mit \(i=1,\ldots,n\) ist jener Wert, den ein Merkmal \(X\) in einer statistischen Untersuchung tatsächlich annimmt. Ziel der deskriptiven Statistik ist es, die Verteilung der Merkmalswerte eines Merkmals über den möglichen Wertebereich (Ausprägungen) mit einzelnen Parametern näher zu charakterisieren. Z.B. die Anzahl der Ausbrüche eines Vulkans an verschiedenen Tagen.
Die Parameter, die uns hier interessieren, sind:
- Lageparameter: Maße der zentralen Tendenz einer Verteilung (s. dieses Kapitel)
- Streuungsparameter: Maße der Variabilität einer Verteilung (s. Kapitel 4)
- Schiefe und Wölbung einer Verteilung (s. Kapitel 4)
Dazu brauchen wir erstmal Begriffe wie absolute Häufigkeit, relative Häufigkeit und Summenhäufigkeit, sowie Diagramme wie Histogramme und Boxplots, die Verteilungen graphisch darstellen.
3.2 Häufigkeiten
Schauen wir uns dazu die Reisedaten an, die Sie eingegeben haben, und zwar nur die Entfernungen (der R-Code wird in den PC-Übungen schnell klar werden):
# Paket laden, das für das Einlesen von xlsx gebraucht wird
library("readxl")
# Daten einlesen
# der Zusatz na = "-999" sagt R, dass fehlende Werte mit -999 kodiert sind
reisedat <- read_excel("data/Daten_Distanz_Reisezeit_2025.xlsx", na = "-999")
# in metrische Skala und data.frame umwandeln
reisedat <- as.data.frame(apply(reisedat, 2, as.numeric))
# Ausgabe von reisedat$distanz
reisedat$distanz## [1] 9.20 12.30 14.10 13.00 17.00 60.80 18.70 10.70
## [9] 9.40 7.70 3.30 5.10 32.10 15.20 24.23 7.80
## [17] 4.70 13.30 14.00 8.90 9.10 11.20 6.40 17.80
## [25] 10.00 22.90 23.00 3.20 15.90 8.20 17.30 35.70
## [33] 27.50 8.60 3.80 14.90 10.00 15.30 25.00 5.80
## [41] 13.50 8.50 15.50 6.50 29.30 2.70 15.70 17.00
## [49] 14.00 13.20 16.10 8.40 11.30 12.60 8.50 13.40
## [57] 18.00 17.60 11.50 12.50 18.00 9.20 13.30Das ist eine ungeordnete Reihe von 63 Datenpunkten, den sogenannten Rohdaten.
Wenn wir die Rohdaten jetzt ordnen und in Klassen einteilen können wir absolute Häufigkeiten bestimmen, gewissermaßen durch Abzählen:
## [1] 2.70 3.20 3.30 3.80 4.70 5.10 5.80 6.40
## [9] 6.50 7.70 7.80 8.20 8.40 8.50 8.50 8.60
## [17] 8.90 9.10 9.20 9.20 9.40 10.00 10.00 10.70
## [25] 11.20 11.30 11.50 12.30 12.50 12.60 13.00 13.20
## [33] 13.30 13.30 13.40 13.50 14.00 14.00 14.10 14.90
## [41] 15.20 15.30 15.50 15.70 15.90 16.10 17.00 17.00
## [49] 17.30 17.60 17.80 18.00 18.00 18.70 22.90 23.00
## [57] 24.23 25.00 27.50 29.30 32.10 35.70 60.80# absolute Häufigkeiten bestimmen für Klassen von 0 bis 80km, mit Breite 5km
hist(reisedat$distanz, breaks = seq(0, 80, 5),
main = "", xlab = "Entfernung (km)",
ylab = "absolute Häufigkeit")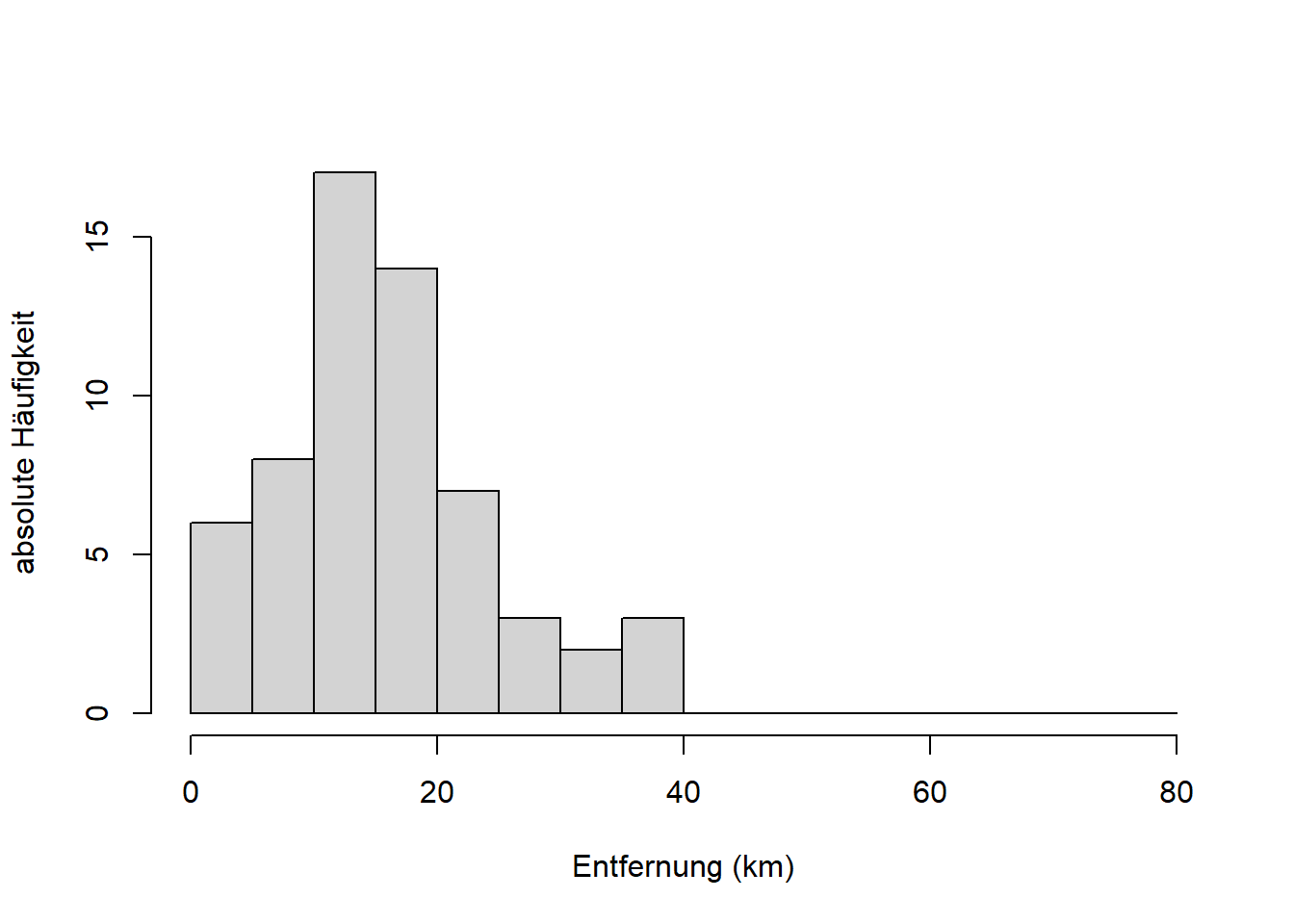
Diese Darstellung ist ein Histogramm. Dazu später mehr. Das Ordnen geschieht bei der Errechnung des Histogramms automatisch, hier haben wir den dazugehörigen R-Code nur der Anschaulichkeit halber eingefügt.
Die absolute Häufigkeit, bezeichnet mit \(h_j\) für \(h\left(a_j\right)\) und \(j=1,\ldots,m\), gibt also die Anzahl der statistischen Einheiten in einer Stichprobe an, welche die Merkmalsausprägung \(a_j\) für ein Merkmal \(X\) annehmen. In unserem Beispiel haben wir die Merkmalsausprägungen durch Klassifizierung gewissermaßen “künstlich” erzeugt, da die Menge der Ausprägungen des Merkmals “Entfernung” ja nicht abzählbar ist. Im Beispiel der Anzahl Vulkanausbrüche in Zimmermann-Janschitz (2014) gibt es dagegen abzählbare Merkmalsausprägungen.
Die Summe der absoluten Häufigkeiten ist der Stichprobenumfang \(n\): \[\sum_{j=1}^{m}h_j=n\]
Die relative Häufigkeit, bezeichnet mit \(f_j\) für \(f\left(a_j\right)\) und \(j=1,\ldots,m\), gibt dann den Anteil der statistischen Einheiten an einer Stichprobe an, welche die Merkmalsausprägung \(a_j\) für ein Merkmal \(X\) annehmen: \[f_j=f\left(a_j\right)=\frac{h\left(a_j\right)}{n}\]
Das Histogramm bleibt gleich, nur dass die vertikale Achse anders skaliert ist. Da das in der hist() Funktion nicht vorgesehen ist, ist der R-Code etwas länger:
# Histogramm berechnen ohne Output
h <- hist(reisedat$distanz, breaks = seq(0, 80, 5), plot = FALSE)
# absolute in relative Häufigkeiten umrechnen
h$counts <- h$counts / sum(h$counts)
# Histogrammdaten plotten
barplot(h$counts ~ h$mids, space = 0, col = "gray",
main = "", xlab = "Entfernung (km)", ylab = "relative Häufigkeit")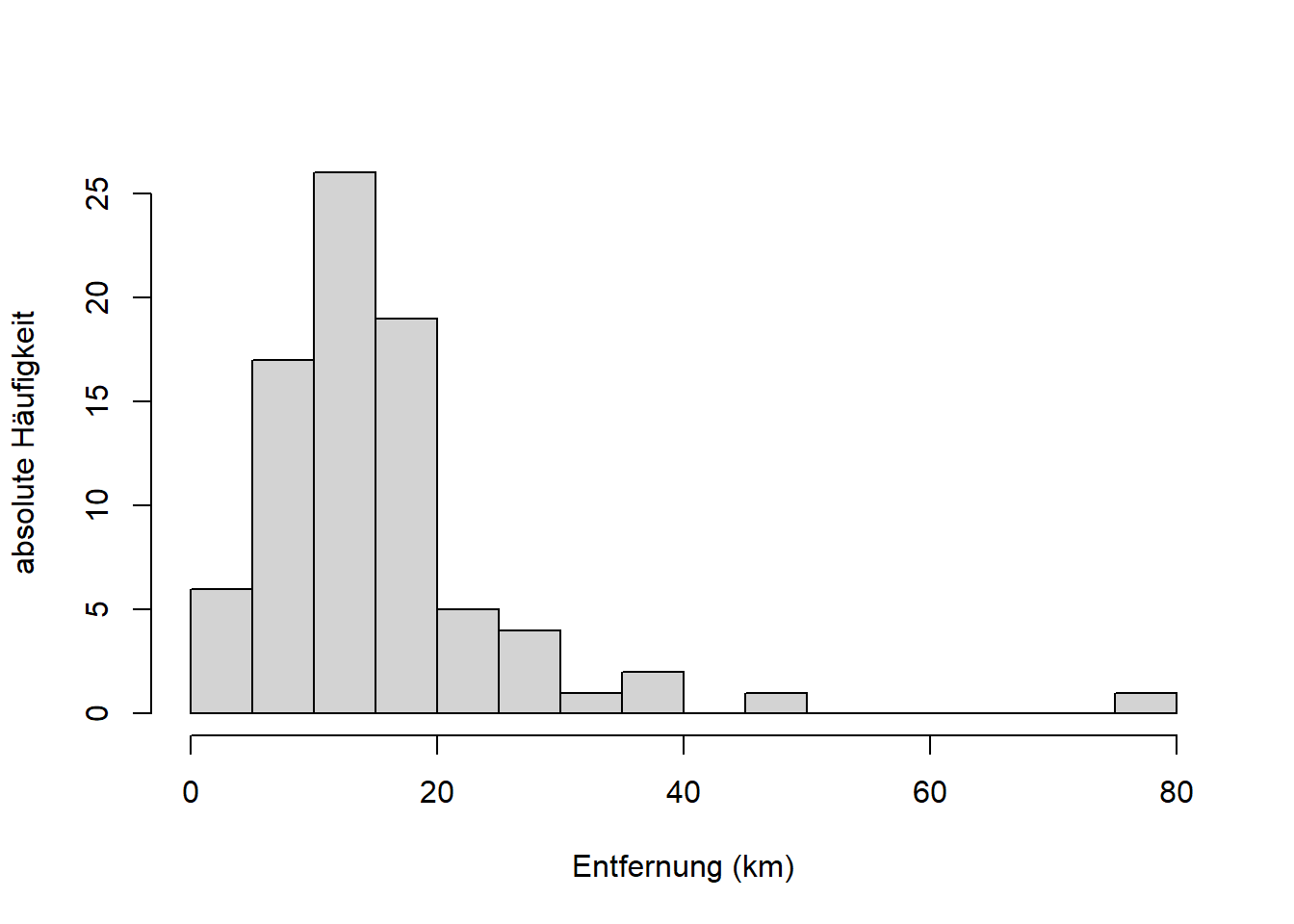
Interpretation: Der erste Balken z.B. geht bis ca. 0.08, d.h. ca. 8% der Entfernungsdaten haben Werte zwischen 0 und 5km. Wenn wir uns das Histogramm der absoluten Häufigkeiten weiter oben anschauen, dann sehen wir, dass das 5 von 63 Datenpunkten sind.
Die Summe der relativen Häufigkeiten ist 1, was 100% entspricht: \[\sum_{j=1}^{m}f_j=1\]
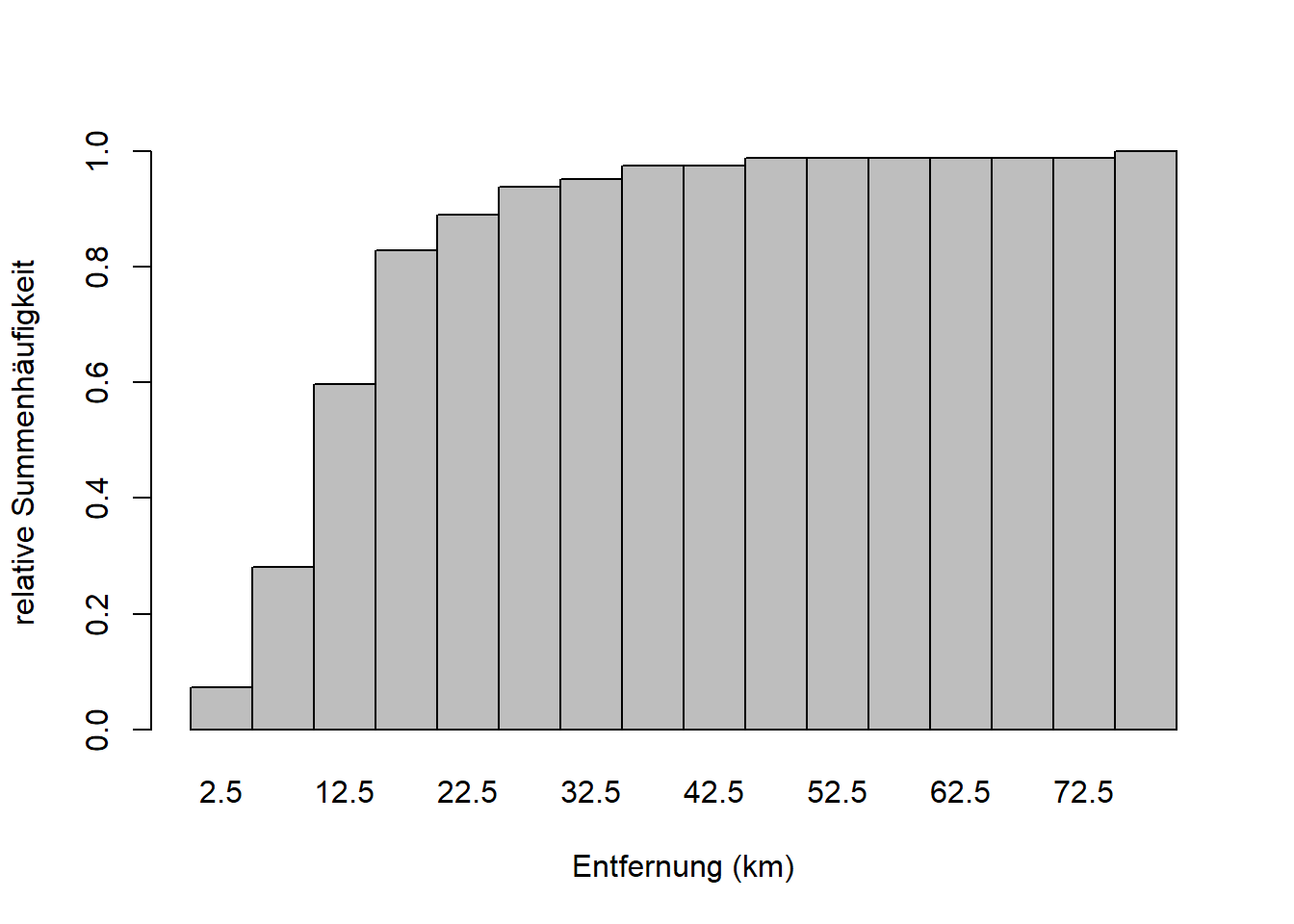
Kommen wir nun zu den Summenhäufigkeiten, auch genannt kumulative Häufigkeiten oder kumulierte Häufigkeiten. Die absolute Summenhäufigkeit einer Merkmalsausprägung \(a_j\) ist die Anzahl der Merkmalswerte, die kleiner oder gleich \(a_j\) sind. Die relative Summenhäufigkeit von \(a_j\) ist dementsprechend der Anteil der Merkmalswerte, die kleiner oder gleich \(a_j\) sind. Am besten visualisieren wir das kurz in R:
# Histogramm berechnen ohne Output
h <- hist(reisedat$distanz, breaks = seq(0, 80, 5), plot = FALSE)
# Häufigkeiten kumuliert aufsummieren
h$counts <- cumsum(h$counts)
# Histogrammdaten plotten
plot(h, freq = TRUE, col = "gray",
main = "", xlab = "Entfernung (km)", ylab = "absolute Summenhäufigkeit")
# absolute Summenhäufigkeiten in relative umrechnen
h$counts <- h$counts / max(h$counts)
# Histogrammdaten plotten
barplot(h$counts ~ h$mids, space = 0, col = "gray",
main = "", xlab = "Entfernung (km)", ylab = "relative Summenhäufigkeit")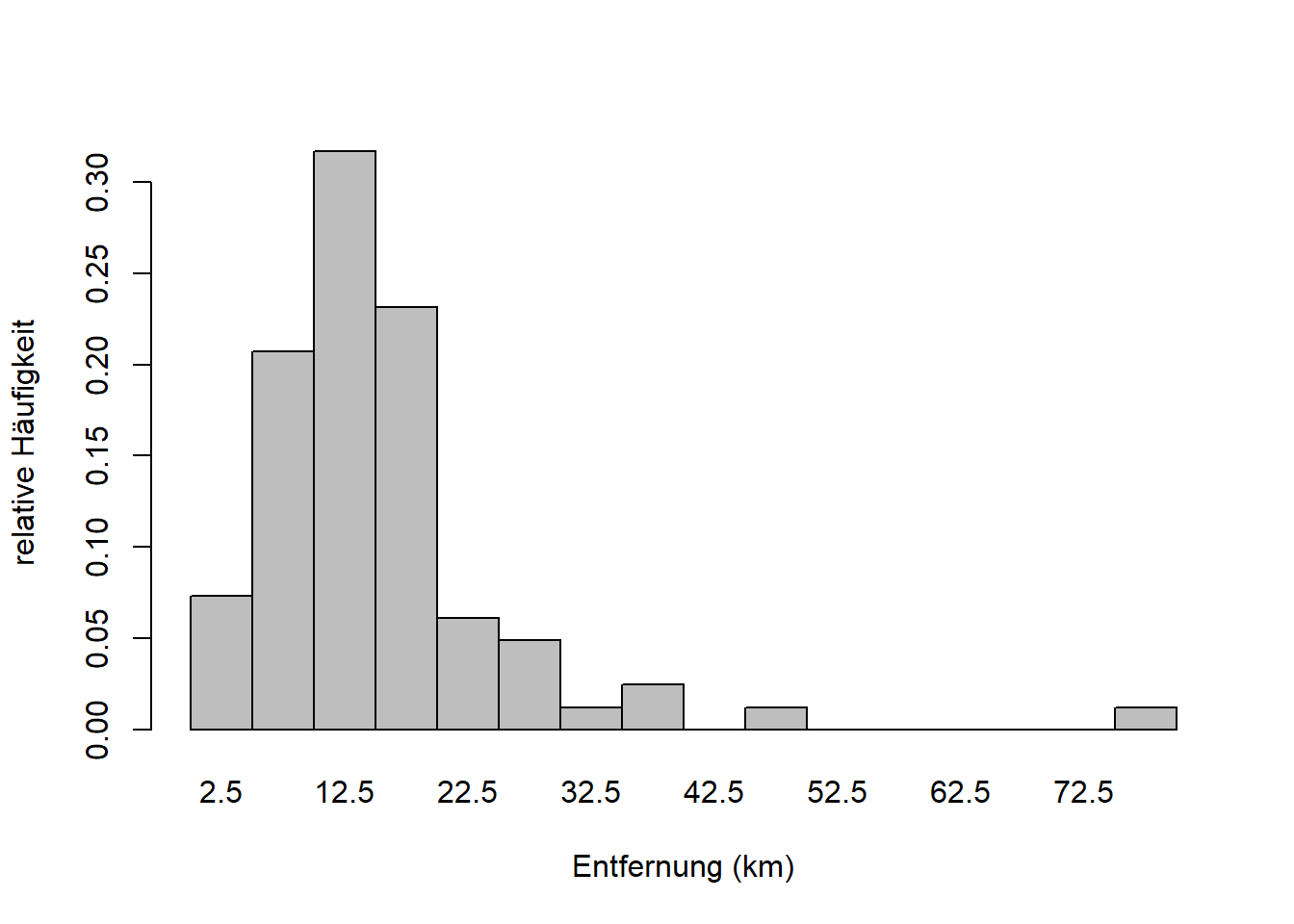
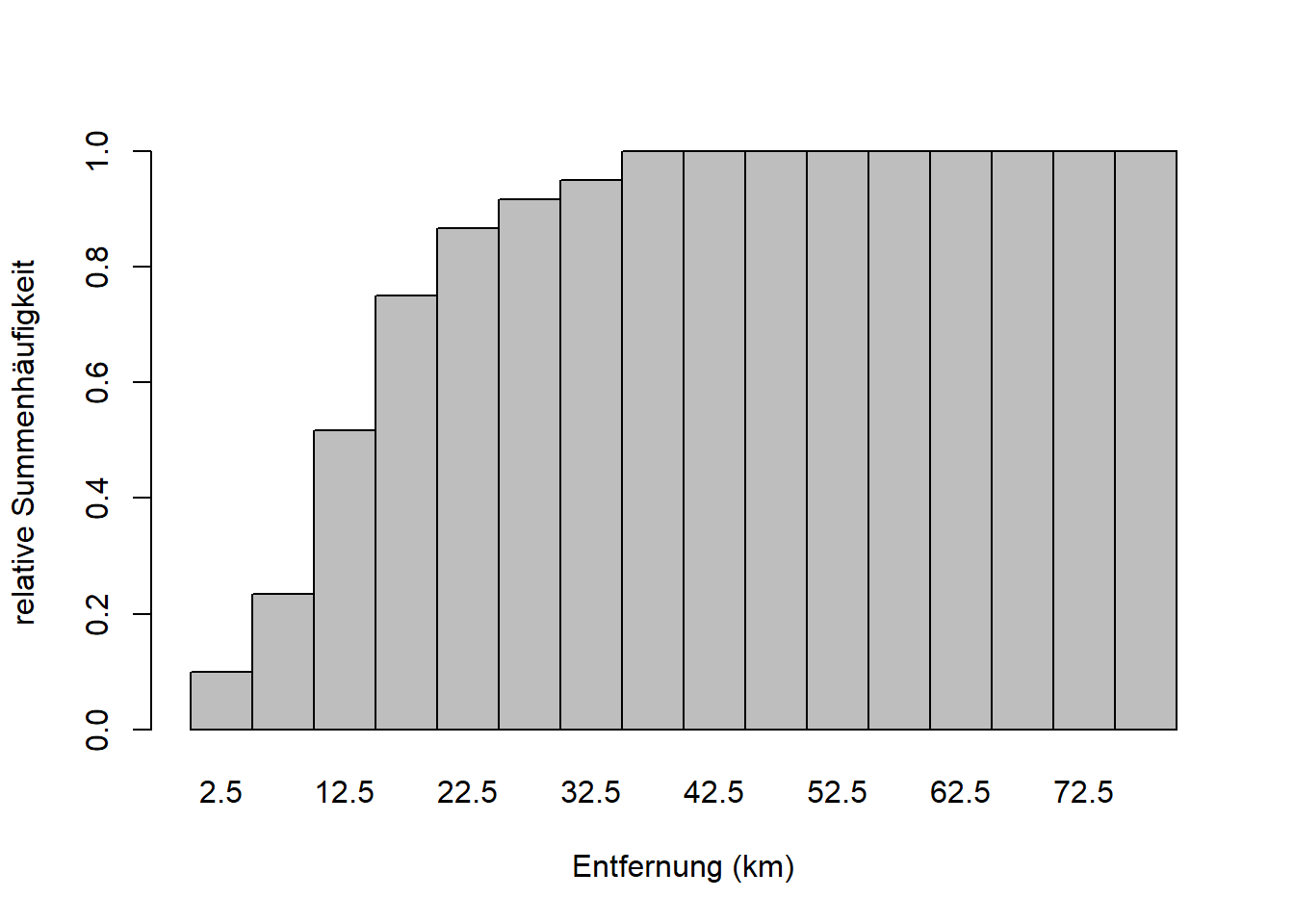
Die Häufigkeiten der Klassen sind hier kumuliert aufsummiert, d.h. der letzte Balken ganz rechts hat die absolute Höhe 63, die Gesamtzahl der Datenpunkte \(n\), bzw. die relative Höhe 1 (100%). Sehen die dazu auch das Beispiel in Zimmermann-Janschitz (2014), Tabelle 3.10 auf Seite 87.
Abschließend noch ein paar Worte zur Klassifizierung. Äquidistante Klassen, d.h. Klassen gleicher Breite, sind grundsätzlich zu bevorzugen. In R können Sie eine gewünschte Anzahl Klassen angeben, die dann äquidistant über den Wertebereich verteilt werden. Das ist sinnvoll für einen ersten Eindruck. Die Grundeinstellung von 10 Klassen ist dabei meist ausreichend. Im Laufe der Analyse wird es manchmal sinnvoller sein, bestimmte Klassen vorzugeben, auch (oder gerade) wenn manche Klassen in der betrachteten Stichprobe nicht vorkommen, wie bei unserem Beispiel der Entfernungsdaten. Sie können in R Klassen vorgeben, indem Sie die Klassengrenzen (“breaks”) angeben. Hier einige Varianten:
# Klassenbreite 5km
hist(reisedat$distanz, breaks = seq(0, 80, 5),
main = "5km Klassenbreite",
xlab = "Entfernung (km)", ylab = "absolute Häufigkeit")
# Klassenbreite 10km
hist(reisedat$distanz, breaks = seq(0, 80, 10),
main = "10km Klassenbreite",
xlab = "Entfernung (km)", ylab = "absolute Häufigkeit")
# Klassenbreite 20km
hist(reisedat$distanz, breaks = seq(0, 80, 20),
main = "20km Klassenbreite",
xlab = "Entfernung (km)", ylab = "absolute Häufigkeit")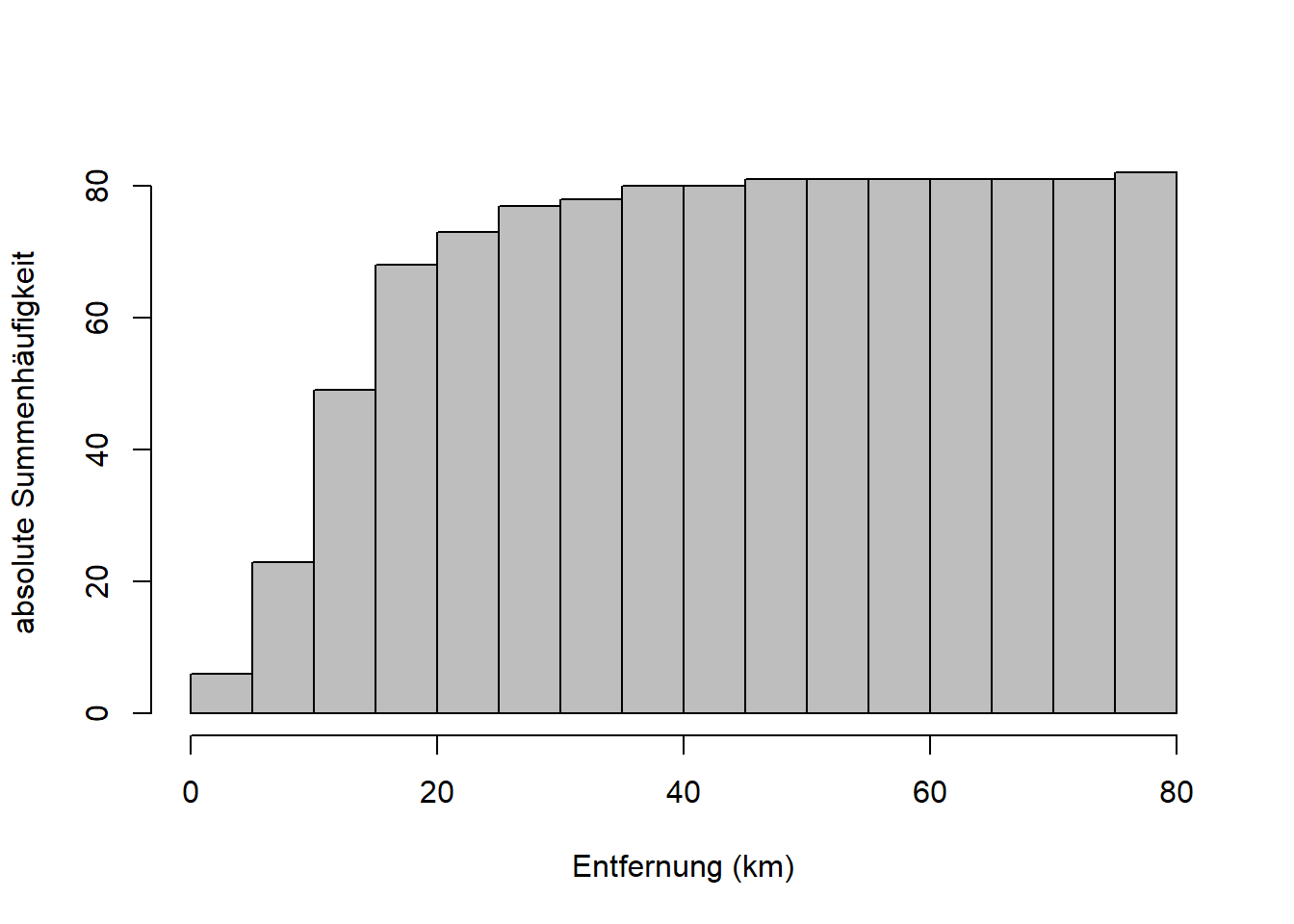
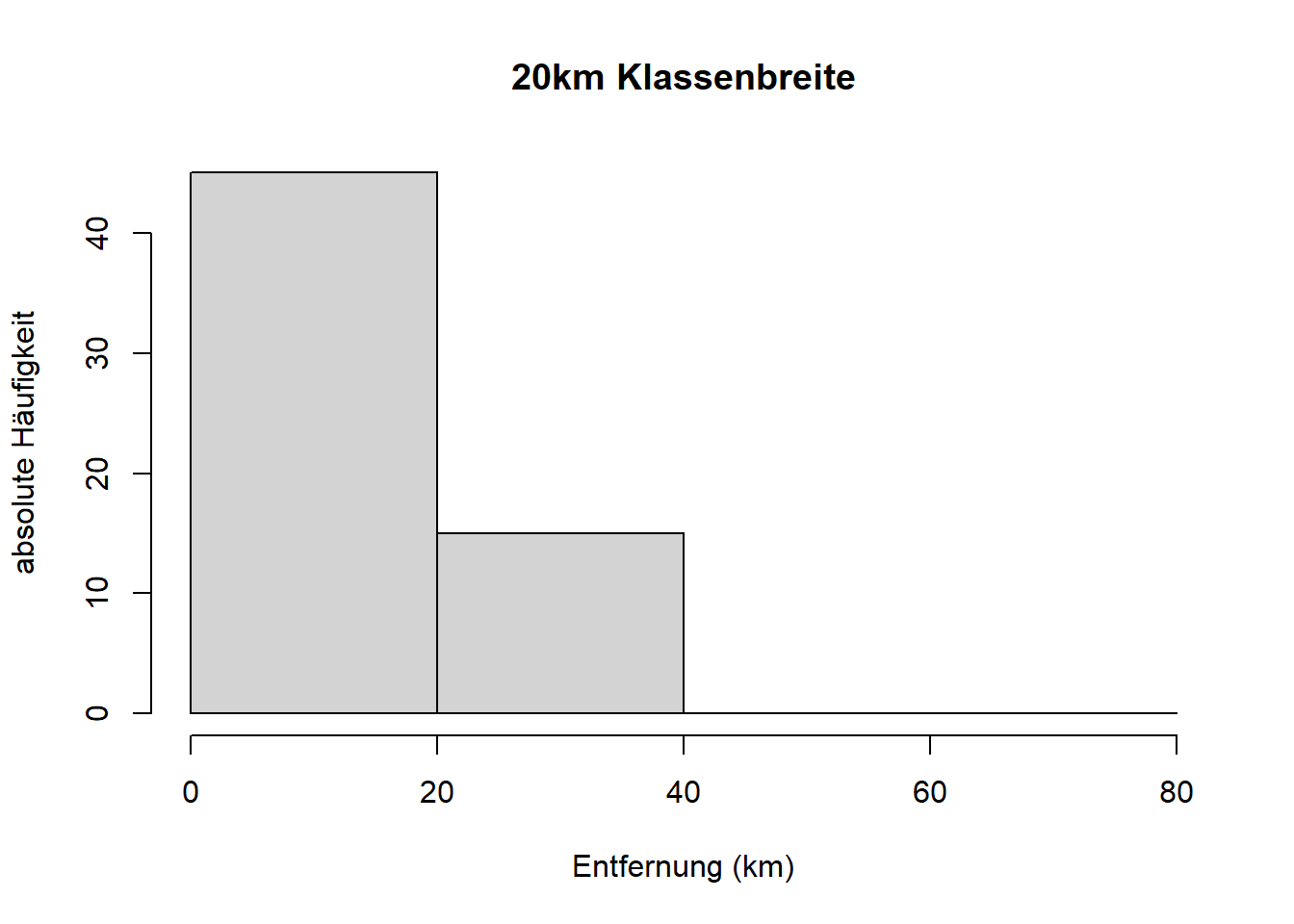
Je größer die Klassenbreite, desto mehr Nuancen der Verteilung der Werte gehen verloren. Je kleiner die Klassenbreite, desto mehr Lücken entstehen im Histogramm und die generelle Form der Verteilung tritt in den Hintergrund. Eine geeignete Klassenbreite wird man nur durch Ausprobieren hinbekommen. Siehe aber Zimmermann-Janschitz (2014), S. 91 - 102 für Richtlinien zur Klassenbildung.
3.3 Lageparameter
Lageparameter sind Maße der zentralen Tendenz einer Häufigkeitsverteilung. Siehe Zimmermann-Janschitz (2014), Kapitel 3.2.2. Wichtig sind uns in dieser Veranstaltung der Modus, das arithmetische Mittel und der Median, weniger das harmonische Mittel und das geometrische Mittel, die Sie aber bei Zimmermann-Janschitz (2014) nachlesen können.
Der Modus \(\bar x_{mod}\) entspricht jener Merkmalsausprägung \(a_j\), die in der Häufigkeitsverteilung (lokal) am häufigsten vorkommt. In unseren Entfernungsdaten wäre das der Wert \(7.5\):
h <- hist(reisedat$distanz, breaks = seq(0, 80, 5), plot = FALSE)
plot(h, freq = TRUE, col = "gray",
main = "", xlab = "Entfernung (km)", ylab = "absolute Häufigkeit")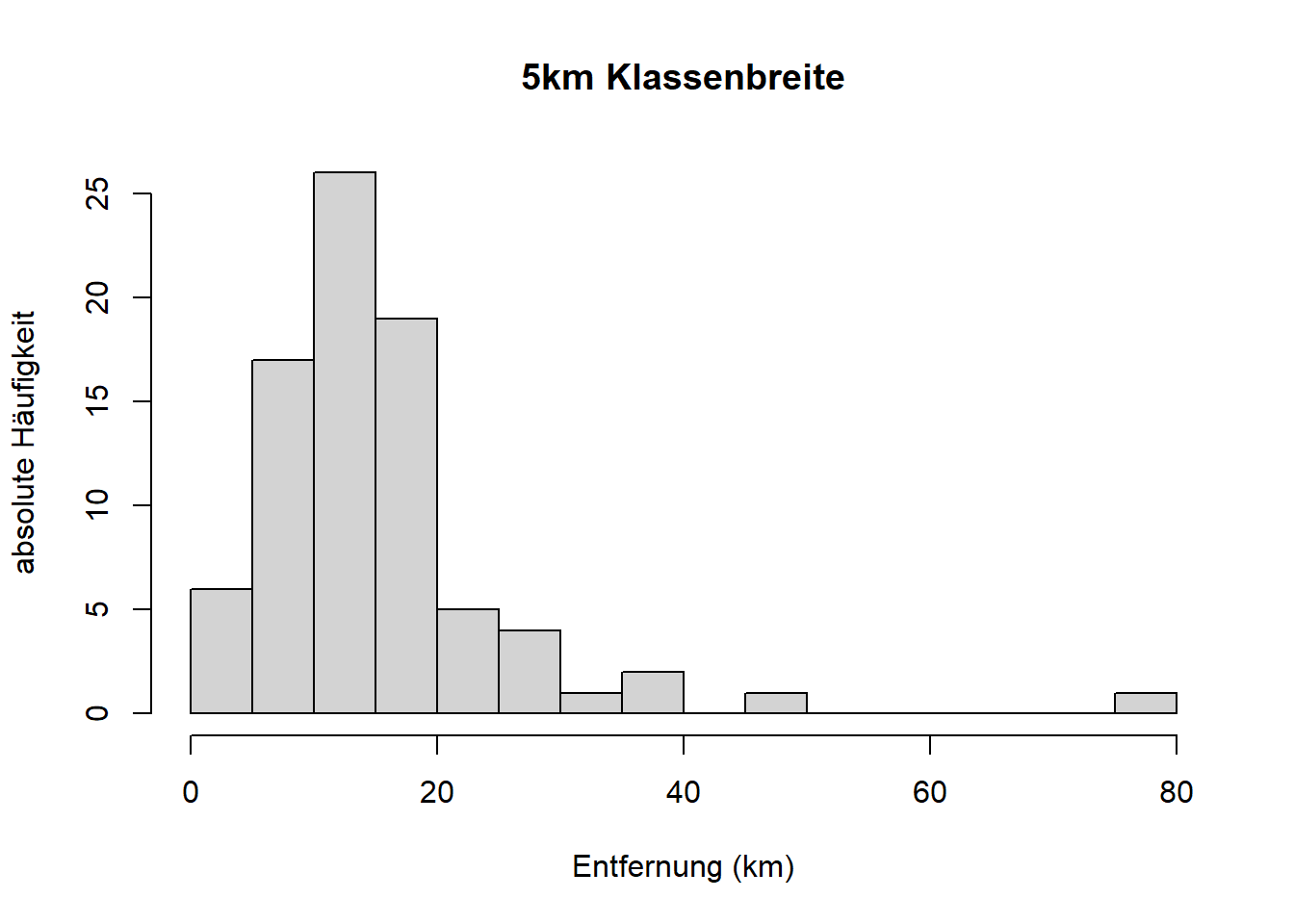
# gib Klassenmitte aus (an der Stelle, wo die Häufigkeiten gleich dem Maximum sind)
h$mids[h$counts == max(h$counts)]## [1] 7.5Bei “künstlichen” Klassen wie in unserem Beispiel wird typischerweise die Mitte der häufigsten Klasse angegeben. Sie sehen also, der Modus ist in diesem Fall abhängig von der gewählten Klassifizierung und nicht eindeutig. Bei Zimmermann-Janschitz (2014), S. 110 - 112 finden Sie eine “Korrektur” des Modus für ungleiche Klassenbreiten; von der Klassenmitte hin zu der Nachbarklasse, die häufiger ist als die andere Nachbarklasse. Mit dem gleichen Argument könnte man auch den Modus bei gleicher Klassenbreite korrigieren. Diese Art der Korrektur des Modus wird aber immer ein Kompromiss bleiben. Deshalb würde ich folgendes empfehlen:
- Ungleiche Klassenbreiten vermeiden.
- Ein Klasse für den Modus (“Modalklasse”) angeben, z.B. für unsere Entfernungsdaten: “Bei einer Klassierung der Entfernungsdaten mit Klassenbreite 5km ist die häufigste Klasse \((5;10]\).”
Im obigen Histogramm der Entfernungsdaten sehen wir außerdem ein weiteres lokales Maximum bei \(62.5\), es handelt sich also in dieser Klassifizierung um eine multimodale Verteilung - eine Verteilung mit mehreren Modi. Der Sonderfall, der hier vorliegt, ist die bimodale Verteilung, die zwei lokale Maxima hat.
Das arithmetische Mittel \(\bar x\) der Merkmalswerte \(x_1, x_2, \ldots, x_n\) ist die Summe aller Merkmalswerte \(x_i\) relativ zur Stichprobengröße \(n\): \[\bar x=\frac{\sum_{i=1}^{n}x_i}{n}\]
Liegen absolute oder relative Häufigkeiten für die Merkmalsausprägungen \(a_j\) vor, kann das arithmetische Mittel \(\bar x\) gewichtet berechnet werden:
\[\bar x=\frac{\sum_{j=1}^{m}a_j\cdot h_j}{n}=\sum_{j=1}^{m}a_j\cdot f_j\]
Berechnen wir das arithmetische Mittel für unsere Entfernungsdaten mit der Funktion mean():
# berechne arithmetisches Mittel für Variable "Distanz" in km
# der Zusatz na.rm = TRUE bedeutet, dass NA-Werte nicht berücksichtigt werden
mean(reisedat$distanz, na.rm = TRUE)## [1] 14.28Andere Mittelwerte sind das geometrische Mittel und das harmonische Mittel, siehe Zimmermann-Janschitz (2014), S. 126 - 134.
Der Median \(\bar x_{med}\) schließlich entspricht jenem Merkmalswert \(x_j\) in einer Häufigkeitsverteilung, der eine geordnete Reihe von Merkmalswerten \(x_1, x_2, \ldots, x_n\) in zwei gleich große Wertebereiche teilt. Für eine ungerade Anzahl von Merkmalswerten entspricht der Median dem in der Mitte liegenden Wert: \[\bar x_{med}=x_{\frac{n+1}{2}}\]
Für eine gerade Anzahl von Merkmalswerten wird der Median aus dem arithmetischen Mittel der beiden in der Mitte liegenden Werte errechnet: \[\bar x_{med}=\frac{x_{\frac{n}{2}}+x_{\frac{n}{2}+1}}{2}\]
Berechnen wir den Median für unsere Entfernungsdaten mit der Funktion median():
## [1] 13.2Der Median wird auch 0.5-Quantil genannt. Allgemein entspricht ein p-Quantil \(\bar x_p\) mit \(0\leq p\leq 1\) jenem Merkmalswert \(x_j\) in einer Häufigkeitsverteilung, der eine geordnete Reihe von Merkmalswerten \(x_1, x_2, \ldots, x_n\) in zwei Wertebereiche teilt, so dass ein Anteil \(p\) der Werte kleiner oder gleich \(x_j\) ist.
Ist das Produkt \(n\cdot p\) nicht ganzzahlig, wird für \(j\) die dem Produkt nächstgrößere Zahl verwendet: \[\bar x_p=x_j\]
Ist das Produkt \(n\cdot p\) ganzzahlig, dann ist \(j=n\cdot p\) und: \[\bar x_p=\frac{x_j+x_{j+1}}{2}\]
Auf Quantile werden wir im Zuge theoretischer Verteilungen noch näher zu sprechen kommen (s. Kapitel 7).